资料
遇到动态页面怎么办,详解渲染页面提取
前面我们已经介绍了 Scrapy 的一些常见用法,包括服务端渲染页面的抓取和 API 的抓取,Scrapy 发起 Request 之后,返回的 Response 里面就包含了想要的结果。
但是现在越来越多的网页都已经演变为 SPA 页面,其页面在浏览器中呈现的结果是经过 JavaScript 渲染得到的,如果我们使用 Scrapy 直接对其进行抓取的话,其结果和使用 requests 没有什么区别。
那我们真的要使用 Scrapy 完成对 JavaScript 渲染页面的抓取应该怎么办呢?
之前我们介绍了 Selenium 和 Pyppeteer 都可以实现 JavaScript 渲染页面的抓取,那用了 Scrapy 之后应该这么办呢?Scrapy 能和 Selenium 或 Pyppeteer 一起使用吗?答案是肯定的,我们可以将 Selenium 或 Pyppeteer 通过 Downloader Middleware 和 Scrapy 融合起来,实现 JavaScript 渲染页面的抓取,本节我们就来了解下它的实现吧。
回顾
在前面我们介绍了 Downloader Middleware 的用法,在 Downloader Middleware 中有三个我们可以实现的方法 process_request、process_response 以及 process_exception 方法。
我们再看下 process_request 方法和其不同的返回值的效果:
-
当返回为 None 时,Scrapy 将继续处理该 Request,接着执行其他 Downloader Middleware 的 process_request 方法,一直到 Downloader 把 Request 执行完后得到 Response 才结束。这个过程其实就是修改 Request 的过程,不同的 Downloader Middleware 按照设置的优先级顺序依次对 Request 进行修改,最后送至 Downloader 执行。
-
当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_request 和 process_exception 方法就不会被继续调用,每个 Downloader Middleware 的 process_response 方法转而被依次调用。调用完毕之后,直接将 Response 对象发送给 Spider 来处理。
-
当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_request 方法会停止执行。这个 Request 会重新放到调度队列里,其实它就是一个全新的 Request,等待被调度。如果被 Scheduler 调度了,那么所有的 Downloader Middleware 的 process_request 方法都会被重新按照顺序执行。
-
如果 IgnoreRequest 异常抛出,则所有的 Downloader Middleware 的 process_exception 方法会依次执行。如果没有一个方法处理这个异常,那么 Request 的 errorback 方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
这里我们注意到第二个选项,当返回结果为 Response 对象时,低优先级的 process_request 方法就不会被继续调用了,这个 Response 对象会直接经由 process_response 方法处理后转交给 Spider 来解析。
然后再接着想一想,process_request 接收的参数是 request,即 Request 对象,怎么会返回 Response 对象呢?原因可想而知了,这个 Request 对象不再经由 Scrapy 的 Downloader 来处理了,而是在 process_request 方法里面直接就完成了 Request 的发送操作,然后在得到了对应的 Response 结果后再将其返回就好了。
那么对于 JavaScript 渲染的页面来说,照这个方法来做,我们就可以把 Selenium 或 Pyppeteer 加载页面的过程在 process_request 方法里面实现,得到网页渲染完后的源代码后直接构造 Response 返回即可,这样我们就完成了借助 Downloader Middleware 实现 Scrapy 爬取动态渲染页面的过程。
案例
本节我们就用实例来讲解一下 Scrapy 和 Pyppeteer 实现 JavaScript 渲染页面抓取的流程。
本节使用的实例网站为 https://dynamic5.scrape.center/,这是一个 JavaScript 渲染页面,其内容是一本本的图书信息。
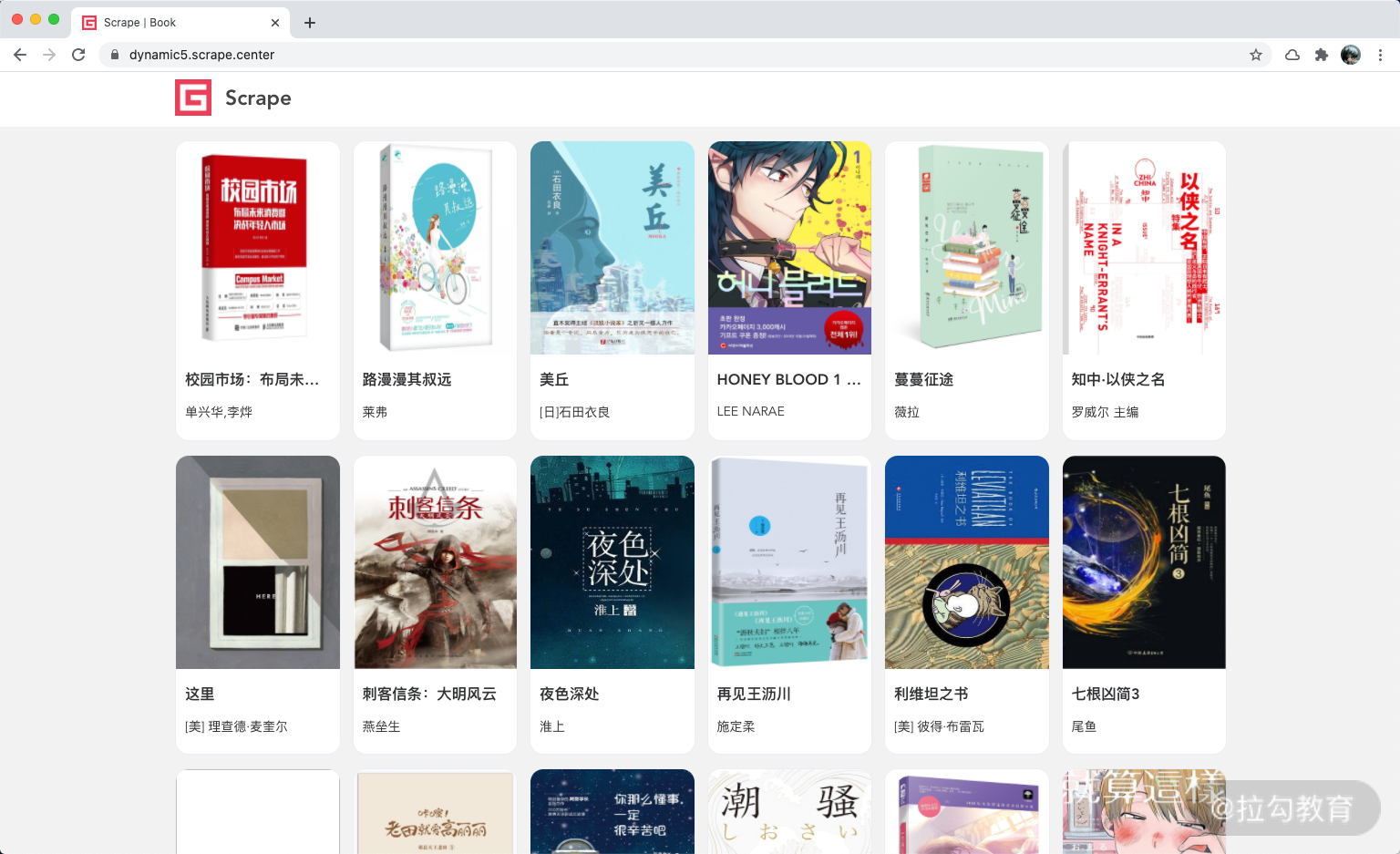
同时这个网站的页面带有分页功能,只需要在 URL 加上 /page/ 和页码就可以跳转到下一页,如 https://dynamic5.scrape.center/page/2 就是第二页内容,https://dynamic5.scrape.center/page/3 就是第三页内容。
那我们这个案例就来试着爬取前十页的图书信息吧。
实现
首先我们来新建一个项目,叫作 scrapypyppeteer,命令如下:
scrapy startproject scrapypyppeteer
接着进入项目,然后新建一个 Spider,名称为 book,命令如下:
cd scrapypyppeteer
scrapy genspider book dynamic5.scrape.center
这时候可以发现在项目的 spiders 文件夹下就出现了一个名为 spider.py 的文件,内容如下:
# -*- coding: utf-8 -*-
import scrapy
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['dynamic5.scrape.center']
start_urls = ['http://dynamic5.scrape.center/']
def parse(self, response):
pass
首先我们构造列表页的初始请求,实现一个 start_requests 方法,如下所示:
# -*- coding: utf-8 -*-
from scrapy import Request, Spider
class BookSpider(Spider):
name = 'book'
allowed_domains = ['dynamic5.scrape.center']
base_url = 'https://dynamic5.scrape.center/page/{page}'
max_page = 10
def start_requests(self):
for page in range(1, self.max_page + 1):
url = self.base_url.format(page=page)
yield Request(url, callback=self.parse_index)
def parse_index(self, response):
print(response.text)
这时如果我们直接运行这个 Spider,在 parse_index 方法里面打印输出 Response 的内容,结果如下:
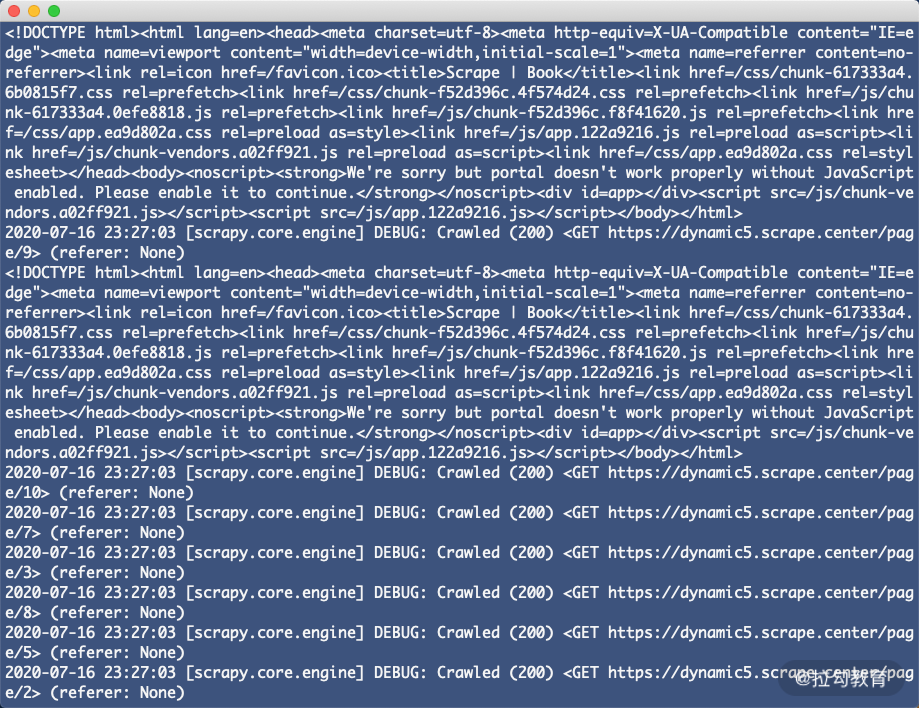
我们可以发现所得到的内容并不是页面渲染后的真正 HTML 代码。此时如果我们想要获取 HTML 渲染结果的话就得使用 Downloader Middleware 实现了。
这里我们直接以一个我已经写好的组件来演示了,组件的名称叫作 GerapyPyppeteer,组件里已经写好了 Scrapy 和 Pyppeteer 结合的中间件,下面我们来详细介绍下。
我们可以借助于 pip3 来安装组件,命令如下:
pip3 install gerapy-pyppeteer
GerapyPyppeteer 提供了两部分内容,一部分是 Downloader Middleware,一部分是 Request。
首先我们需要开启中间件,在 settings 里面开启 PyppeteerMiddleware,配置如下:
DOWNLOADER_MIDDLEWARES = {
'gerapy_pyppeteer.downloadermiddlewares.PyppeteerMiddleware': 543,
}
然后我们把上文定义的 Request 修改为 PyppeteerRequest 即可:
# -*- coding: utf-8 -*-
from gerapy_pyppeteer import PyppeteerRequest
from scrapy import Request, Spider
class BookSpider(Spider):
name = 'book'
allowed_domains = ['dynamic5.scrape.center']
base_url = 'https://dynamic5.scrape.center/page/{page}'
max_page = 10
def start_requests(self):
for page in range(1, self.max_page + 1):
url = self.base_url.format(page=page)
yield PyppeteerRequest(url, callback=self.parse_index, wait_for='.item .name')
def parse_index(self, response):
print(response.text)
这样其实就完成了 Pyppeteer 的对接了,非常简单。
这里 PyppeteerRequest 和原本的 Request 多提供了一个参数,就是 wait_for,通过这个参数我们可以指定 Pyppeteer 需要等待特定的内容加载出来才算结束,然后才返回对应的结果。
为了方便观察效果,我们把并发限制修改得小一点,然后把 Pyppeteer 的 Headless 模式设置为 False:
CONCURRENT_REQUESTS = 3
GERAPY_PYPPETEER_HEADLESS = False
这时我们重新运行 Spider,就可以看到在爬取的过程中,Pyppeteer 对应的 Chromium 浏览器就弹出来了,并逐个加载对应的页面内容,加载完成之后浏览器关闭。
另外观察下控制台,我们发现对应的结果也就被提取出来了,如图所示:

这时候我们再重新修改下 parse_index 方法,提取对应的每本书的名称和作者即可:
def parse_index(self, response):
for item in response.css('.item'):
name = item.css('.name::text').extract_first()
authors = item.css('.authors::text').extract_first()
name = name.strip() if name else None
authors = authors.strip() if authors else None
yield {
'name': name,
'authors': authors
}
重新运行,即可发现对应的名称和作者就被提取出来了,运行结果如下:
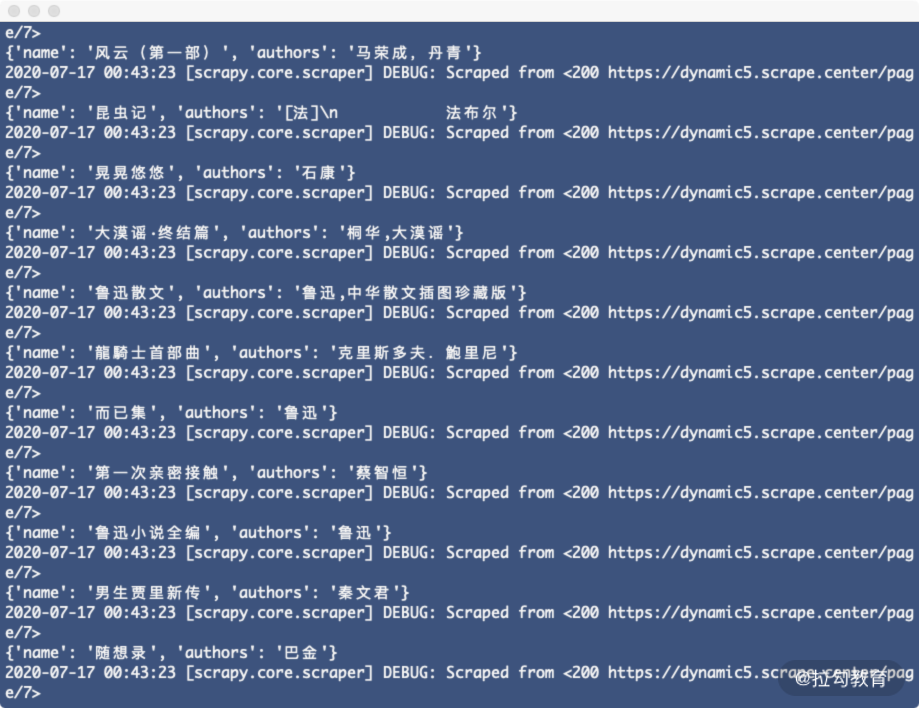
这样我们就借助 GerapyPyppeteer 完成了 JavaScript 渲染页面的爬取。
原理分析
但上面仅仅是我们借助 GerapyPyppeteer 实现了 Scrapy 和 Pyppeteer 的对接,但其背后的原理是怎样的呢?
我们可以详细分析它的源码,其 GitHub 地址为 https://github.com/Gerapy/GerapyPyppeteer。
首先通过分析可以发现其最核心的内容就是实现了一个 PyppeteerMiddleware,这是一个 Downloader Middleware,这里最主要的就是 process_request 的实现,核心代码如下所示:
def process_request(self, request, spider):
logger.debug('processing request %s', request)
return as_deferred(self._process_request(request, spider))
这里其实就是调用了一个 _process_request 方法,这个方法的返回结果被 as_deferred 方法调用了。
这个 as_deferred 是怎么定义的呢?代码如下:
import asyncio
from twisted.internet.defer import Deferred
def as_deferred(f):
return Deferred.fromFuture(asyncio.ensure_future(f))
这个方法接收的就是一个 asyncio 库的 Future 对象,然后通过 fromFuture 方法转化成了 twisted 里面的 Deferred 对象。这是因为 Scrapy 本身的异步是借助 twisted 实现的,一个个的异步任务对应的就是一个个 Deferred 对象,而 Pyppeteer 又是基于 asyncio 的,它的异步任务是 Future 对象,所以这里我们需要借助 Deferred 的 fromFuture 方法将 Future 转为 Deferred 对象。
另外为了支持这个功能,我们还需要在 Scrapy 中修改 reactor 对象,修改为 AsyncioSelectorReactor,实现如下:
import sys
from twisted.internet.asyncioreactor import AsyncioSelectorReactor
import twisted.internet
reactor = AsyncioSelectorReactor(asyncio.get_event_loop())
# install AsyncioSelectorReactor
twisted.internet.reactor = reactor
sys.modules['twisted.internet.reactor'] = reactor
这段代码已经在 PyppeteerMiddleware 里面定义好了,在 Scrapy 正式开始爬取之前这段代码就会被执行,将 Scrapy 中的 reactor 修改为 AsyncioSelectorReactor,从而实现 Future 的调度。
接下来我们再来看下 _process_request 方法,实现如下:
async def _process_request(self, request: PyppeteerRequest, spider):
"""
use pyppeteer to process spider
:param request:
:param spider:
:return:
"""
options = {
'headless': self.headless,
'dumpio': self.dumpio,
'devtools': self.devtools,
'args': [
f'--window-size={self.window_width},{self.window_height}',
]
}
if self.executable_path: options['executable_path'] = self.executable_path
if self.disable_extensions: options['args'].append('--disable-extensions')
if self.hide_scrollbars: options['args'].append('--hide-scrollbars')
if self.mute_audio: options['args'].append('--mute-audio')
if self.no_sandbox: options['args'].append('--no-sandbox')
if self.disable_setuid_sandbox: options['args'].append('--disable-setuid-sandbox')
if self.disable_gpu: options['args'].append('--disable-gpu')
# set proxy
proxy = request.proxy
if not proxy:
proxy = request.meta.get('proxy')
if proxy: options['args'].append(f'--proxy-server={proxy}')
logger.debug('set options %s', options)
browser = await launch(options)
page = await browser.newPage()
await page.setViewport({'width': self.window_width, 'height': self.window_height})
# set cookies
if isinstance(request.cookies, dict):
await page.setCookie(*[
{'name': k, 'value': v}
for k, v in request.cookies.items()
])
else:
await page.setCookie(request.cookies)
# the headers must be set using request interception
await page.setRequestInterception(True)
@page.on('request')
async def _handle_interception(pu_request):
# handle headers
overrides = {
'headers': {
k.decode(): ','.join(map(lambda v: v.decode(), v))
for k, v in request.headers.items()
}
}
# handle resource types
_ignore_resource_types = self.ignore_resource_types
if request.ignore_resource_types is not None:
_ignore_resource_types = request.ignore_resource_types
if pu_request.resourceType in _ignore_resource_types:
await pu_request.abort()
else:
await pu_request.continue_(overrides)
timeout = self.download_timeout
if request.timeout is not None:
timeout = request.timeout
logger.debug('crawling %s', request.url)
response = None
try:
options = {
'timeout': 1000 * timeout,
'waitUntil': request.wait_until
}
logger.debug('request %s with options %s', request.url, options)
response = await page.goto(
request.url,
options=options
)
except (PageError, TimeoutError):
logger.error('error rendering url %s using pyppeteer', request.url)
await page.close()
await browser.close()
return self._retry(request, 504, spider)
if request.wait_for:
try:
logger.debug('waiting for %s finished', request.wait_for)
await page.waitFor(request.wait_for)
except TimeoutError:
logger.error('error waiting for %s of %s', request.wait_for, request.url)
await page.close()
await browser.close()
return self._retry(request, 504, spider)
# evaluate script
if request.script:
logger.debug('evaluating %s', request.script)
await page.evaluate(request.script)
# sleep
if request.sleep is not None:
logger.debug('sleep for %ss', request.sleep)
await asyncio.sleep(request.sleep)
content = await page.content()
body = str.encode(content)
# close page and browser
logger.debug('close pyppeteer')
await page.close()
await browser.close()
if not response:
logger.error('get null response by pyppeteer of url %s', request.url)
# Necessary to bypass the compression middleware (?)
response.headers.pop('content-encoding', None)
response.headers.pop('Content-Encoding', None)
return HtmlResponse(
page.url,
status=response.status,
headers=response.headers,
body=body,
encoding='utf-8',
request=request
)
代码内容比较多,我们慢慢来说。
首先最开始的部分是定义 Pyppeteer 的一些启动参数:
options = {
'headless': self.headless,
'dumpio': self.dumpio,
'devtools': self.devtools,
'args': [
f'--window-size={self.window_width},{self.window_height}',
]
}
if self.executable_path: options['executable_path'] = self.executable_path
if self.disable_extensions: options['args'].append('--disable-extensions')
if self.hide_scrollbars: options['args'].append('--hide-scrollbars')
if self.mute_audio: options['args'].append('--mute-audio')
if self.no_sandbox: options['args'].append('--no-sandbox')
if self.disable_setuid_sandbox: options['args'].append('--disable-setuid-sandbox')
if self.disable_gpu: options['args'].append('--disable-gpu')
这些参数来自 from_crawler 里面读取项目 settings 的内容,如配置 Pyppeteer 对应浏览器的无头模式、窗口大小、是否隐藏滚动条、是否弃用沙箱,等等。
紧接着就是利用 options 来启动 Pyppeteer:
browser = await launch(options)
page = await browser.newPage()
await page.setViewport({'width': self.window_width, 'height': self.window_height})
这里启动了 Pyppeteer 对应的浏览器,将其赋值为 browser,然后新建了一个选项卡,赋值为 page,然后通过 setViewport 方法设定了窗口的宽高。
接下来就是对一些 Cookies 进行处理,如果 Request 带有 Cookies 的话会被赋值到 Pyppeteer 中:
# set cookies
if isinstance(request.cookies, dict):
await page.setCookie(*[
{'name': k, 'value': v}
for k, v in request.cookies.items()
])
else:
await page.setCookie(request.cookies)
再然后关键的步骤就是进行页面的加载了:
try:
options = {
'timeout': 1000 * timeout,
'waitUntil': request.wait_until
}
logger.debug('request %s with options %s', request.url, options)
response = await page.goto(
request.url,
options=options
)
except (PageError, TimeoutError):
logger.error('error rendering url %s using pyppeteer', request.url)
await page.close()
await browser.close()
return self._retry(request, 504, spider)
这里我们首先制定了加载超时时间 timeout 还有要等待完成的事件 waitUntil,接着调用 page 的 goto 方法访问对应的页面,同时进行了异常检测,如果发生错误就关闭浏览器并重新发起一次重试请求。
在页面加载出来之后,我们还需要判定我们期望的结果是不是加载出来了,所以这里又增加了 waitFor 的调用:
if request.wait_for:
try:
logger.debug('waiting for %s finished', request.wait_for)
await page.waitFor(request.wait_for)
except TimeoutError:
logger.error('error waiting for %s of %s', request.wait_for, request.url)
await page.close()
await browser.close()
return self._retry(request, 504, spider)
这里 request 有个 wait_for 属性,就可以定义想要加载的节点的选择器,如 .item .name 等,这样如果页面在规定时间内加载出来就会继续向下执行,否则就会触发 TimeoutError 并被捕获,关闭浏览器并重新发起一次重试请求。
等想要的结果加载出来之后,我们还可以执行一些自定义的 JavaScript 代码完成我们想要自定义的功能:
# evaluate script
if request.script:
logger.debug('evaluating %s', request.script)
await page.evaluate(request.script)
最后关键的一步就是将当前页面的源代码打印出来,然后构造一个 HtmlResponse 返回即可:
content = await page.content()
body = str.encode(content)
# close page and browser
logger.debug('close pyppeteer')
await page.close()
await browser.close()
if not response:
logger.error('get null response by pyppeteer of url %s', request.url)
# Necessary to bypass the compression middleware (?)
response.headers.pop('content-encoding', None)
response.headers.pop('Content-Encoding', None)
return HtmlResponse(
page.url,
status=response.status,
headers=response.headers,
body=body,
encoding='utf-8',
request=request
)
所以,如果代码可以执行到最后,返回到就是一个 Response 对象,这个 Resposne 对象的 body 就是 Pyppeteer 渲染页面后的结果,因此这个 Response 对象再传给 Spider 解析,就是 JavaScript 渲染后的页面结果了。
这样我们就通过 Downloader Middleware 通过对接 Pyppeteer 完成 JavaScript 动态渲染页面的抓取了。
大幅提速,分布式爬虫理念
我们在前面几节课了解了 Scrapy 爬虫框架的用法。但这些框架都是在同一台主机上运行的,爬取效率比较低。如果能够实现多台主机协同爬取,那么爬取效率必然会成倍增长,这就是分布式爬虫的优势。
接下来我们就来了解一下分布式爬虫的基本原理,以及 Scrapy 实现分布式爬虫的流程。
我们在前面已经实现了 Scrapy 基本的爬虫功能,虽然爬虫是异步加多线程的,但是我们却只能在一台主机上运行,所以爬取效率还是有限的,而分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。
分布式爬虫架构
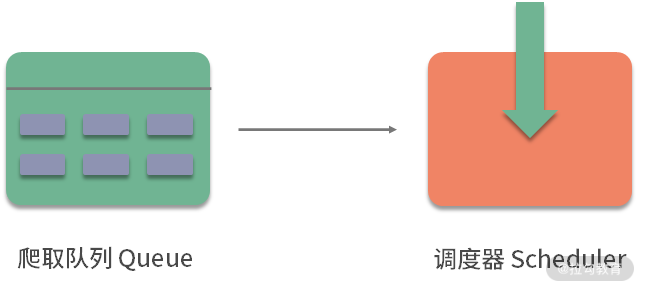
在了解分布式爬虫架构之前,首先回顾一下 Scrapy 的架构,如图所示。
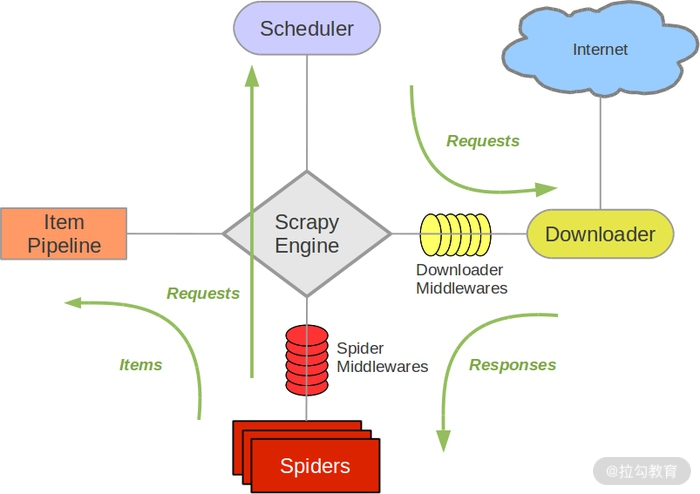
Scrapy 单机爬虫中有一个本地爬取队列 Queue,这个队列是利用 deque 模块实现的。如果新的 Request 生成就会放到队列里面,随后 Request 被 Scheduler 调度。之后,Request 交给 Downloader 执行爬取,简单的调度架构如图所示。
如果两个 Scheduler 同时从队列里面获取 Request,每个 Scheduler 都会有其对应的 Downloader,那么在带宽足够、正常爬取且不考虑队列存取压力的情况下,爬取效率会有什么变化呢?没错,爬取效率会翻倍。
这样,Scheduler 可以扩展多个,Downloader 也可以扩展多个。而爬取队列 Queue 必须始终为一个,也就是所谓的共享爬取队列。这样才能保证 Scheduer 从队列里调度某个 Request 之后,其他 Scheduler 不会重复调度此 Request,就可以做到多个 Schduler 同步爬取。这就是分布式爬虫的基本雏形,简单调度架构如图所示。
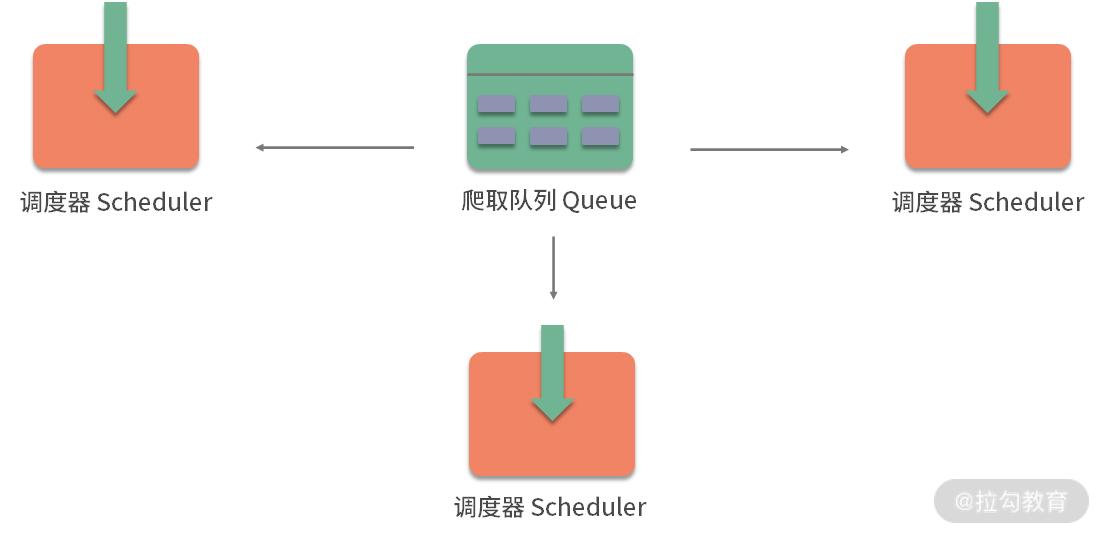
我们需要做的就是在多台主机上同时运行爬虫任务协同爬取,而协同爬取的前提就是共享爬取队列。这样各台主机就不需要维护各自的爬取队列了,而是从共享爬取队列存取 Request。但是各台主机还有各自的 Scheduler 和 Downloader,所以调度和下载功能是分别完成的。如果不考虑队列存取性能消耗,爬取效率还是可以成倍提高的。
维护爬取队列
那么如何维护这个队列呢?我们首先需要考虑的就是性能问题,那什么数据库存取效率高呢?这时我们自然想到了基于内存存储的 Redis,而且 Redis 还支持多种数据结构,例如列表 List、集合 Set、有序集合 Sorted Set 等,存取的操作也非常简单,所以在这里我们采用 Redis 来维护爬取队列。
这几种数据结构存储实际各有千秋,分析如下:
-
列表数据结构有 lpush、lpop、rpush、rpop 方法,所以我们可以用它实现一个先进先出的爬取队列,也可以实现一个先进后出的栈式爬取队列。
-
集合的元素是无序且不重复的,这样我们就可以非常方便地实现一个随机排序的不重复的爬取队列。
-
有序集合带有分数表示,而 Scrapy 的 Request 也有优先级的控制,所以我们用有序集合就可以实现一个带优先级调度的队列。
这些不同的队列我们需要根据具体爬虫的需求灵活选择。
怎样去重
Scrapy 有自动去重功能,它的去重使用了 Python 中的集合。这个集合记录了 Scrapy 中每个 Request 的指纹,这个指纹实际上就是 Request 的散列值。我们可以看看 Scrapy 的源代码,如下所示:
import hashlib
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
request_fingerprint 就是计算 Request 指纹的方法,其方法内部使用的是 hashlib 的 sha1 方法。计算的字段包括 Request 的 Method、URL、Body、Headers 这几部分内容,这里只要有一点不同,那么计算的结果就不同。计算得到的结果是加密后的字符串,也就是指纹。每个 Request 都有独有的指纹,指纹就是一个字符串,判定字符串是否重复比判定 Request 对象是否重复容易得多,所以指纹可以作为判定 Request 是否重复的依据。
那么我们如何判定是否重复呢?Scrapy 是这样实现的,如下所示:
def __init__(self):
self.fingerprints = set()
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
在去重的类 RFPDupeFilter 中,有一个 request_seen 方法,这个方法有一个参数 request,它的作用就是检测该 Request 对象是否重复。这个方法调用 request_fingerprint 获取该 Request 的指纹,检测这个指纹是否存在于 fingerprints 变量中,而 fingerprints 是一个集合,集合的元素都是不重复的。如果指纹存在,那么就返回 True,说明该 Request 是重复的,否则将这个指纹加入集合中。如果下次还有相同的 Request 传递过来,指纹也是相同的,那么这时指纹就已经存在于集合中,Request 对象就会直接判定为重复。这样去重的目的就实现了。
Scrapy 的去重过程就是,利用集合元素的不重复特性来实现 Request 的去重。
对于分布式爬虫来说,我们肯定不能再使用每个爬虫各自的集合来去重了。因为这样还是每台主机单独维护自己的集合,不能做到共享。多台主机如果生成了相同的 Request,只能各自去重,各个主机之间就无法做到去重了。
那么要实现多台主机去重,这个指纹集合也需要是共享的,Redis 正好有集合的存储数据结构,我们可以利用 Redis 的集合作为指纹集合,那么这样去重集合也是共享的。每台主机新生成 Request 之后,会把该 Request 的指纹与集合比对,如果指纹已经存在,说明该 Request 是重复的,否则将 Request 的指纹加入这个集合中即可。利用同样的原理不同的存储结构我们也可以实现分布式 Reqeust 的去重。
防止中断
在 Scrapy 中,爬虫运行时的 Request 队列放在内存中。爬虫运行中断后,这个队列的空间就被释放,此队列就被销毁了。所以一旦爬虫运行中断,爬虫再次运行就相当于全新的爬取过程。
要做到中断后继续爬取,我们可以将队列中的 Request 保存起来,下次爬取直接读取保存数据即可获取上次爬取的队列。我们在 Scrapy 中指定一个爬取队列的存储路径即可,这个路径使用 JOB_DIR 变量来标识,我们可以用如下命令来实现:
scrapy crawl spider -s JOBDIR=crawls/spider
更加详细的使用方法可以参见官方文档,链接为:https://doc.scrapy.org/en/latest/topics/jobs.html。
在 Scrapy 中,我们实际是把爬取队列保存到本地,第二次爬取直接读取并恢复队列即可。那么在分布式架构中我们还用担心这个问题吗?不需要。因为爬取队列本身就是用数据库保存的,如果爬虫中断了,数据库中的 Request 依然是存在的,下次启动就会接着上次中断的地方继续爬取。
所以,当 Redis 的队列为空时,爬虫会重新爬取;当 Redis 的队列不为空时,爬虫便会接着上次中断之处继续爬取。
架构实现
我们接下来就需要在程序中实现这个架构了。首先需要实现一个共享的爬取队列,还要实现去重功能。另外,还需要重写一个 Scheduer 的实现,使之可以从共享的爬取队列存取 Request。
幸运的是,已经有人实现了这些逻辑和架构,并发布成了叫作 Scrapy-Redis 的 Python 包。
在下一节,我们便看看 Scrapy-Redis 的源码实现,以及它的详细工作原理。
分布式利器Scrapy-Redis原理
在上节课我们提到过,Scrapy-Redis 库已经为我们提供了 Scrapy 分布式的队列、调度器、去重等功能,其 GitHub 地址为: https://github.com/rmax/scrapy-redis。
本节课我们深入掌握利用 Redis 实现 Scrapy 分布式的方法,并深入了解 Scrapy-Redis 的原理。
获取源码
可以把源码克隆下来,执行如下命令:
git clone https://github.com/rmax/scrapy-redis.git
核心源码在 scrapy-redis/src/scrapy_redis 目录下。
爬取队列
我们从爬取队列入手,来看看它的具体实现。源码文件为 queue.py,它包含了三个队列的实现,首先它实现了一个父类 Base,提供一些基本方法和属性,如下所示:
class Base(object):
"""Per-spider base queue class"""
def __init__(self, server, spider, key, serializer=None):
if serializer is None:
serializer = picklecompat
if not hasattr(serializer, 'loads'):
raise TypeError("serializer does not implement 'loads' function: % r"
% serializer)
if not hasattr(serializer, 'dumps'):
raise TypeError("serializer '% s' does not implement 'dumps' function: % r"
% serializer)
self.server = server
self.spider = spider
self.key = key % {'spider': spider.name}
self.serializer = serializer
def _encode_request(self, request):
obj = request_to_dict(request, self.spider)
return self.serializer.dumps(obj)
def _decode_request(self, encoded_request):
obj = self.serializer.loads(encoded_request)
return request_from_dict(obj, self.spider)
def __len__(self):
"""Return the length of the queue"""
raise NotImplementedError
def push(self, request):
"""Push a request"""
raise NotImplementedError
def pop(self, timeout=0):
"""Pop a request"""
raise NotImplementedError
def clear(self):
"""Clear queue/stack"""
self.server.delete(self.key)
首先看一下 _encode_request 和 _decode_request 方法,因为我们需要把一个 Request 对象存储到数据库中,但数据库无法直接存储对象,所以需要将 Request 序列转化成字符串再存储,而这两个方法分别是序列化和反序列化的操作,利用 pickle 库来实现,一般在调用 push 将 Request 存入数据库时会调用 _encode_request 方法进行序列化,在调用 pop 取出 Request 的时候会调用 _decode_request 进行反序列化。
在父类中 __len__、push 和 pop 方法都是未实现的,会直接抛出 NotImplementedError,因此是不能直接使用这个类的,必须实现一个子类来重写这三个方法,而不同的子类就会有不同的实现,也就有着不同的功能。
接下来我们就需要定义一些子类来继承 Base 类,并重写这几个方法,那在源码中就有三个子类的实现,它们分别是 FifoQueue、PriorityQueue、LifoQueue,我们分别来看下它们的实现原理。
首先是 FifoQueue:
class FifoQueue(Base):
"""Per-spider FIFO queue"""
def __len__(self):
"""Return the length of the queue"""
return self.server.llen(self.key)
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.brpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.rpop(self.key)
if data:
return self._decode_request(data)
可以看到这个类继承了 Base 类,并重写了 __len__、push、pop 这三个方法,在这三个方法中都是对 server 对象的操作,而 server 对象就是一个 Redis 连接对象,我们可以直接调用其操作 Redis 的方法对数据库进行操作,可以看到这里的操作方法有 llen、lpush、rpop 等,这就代表此爬取队列是使用的 Redis 的列表,序列化后的 Request 会被存入列表中,就是列表的其中一个元素,__len__ 方法是获取列表的长度,push 方法中调用了 lpush 操作,这代表从列表左侧存入数据,pop 方法中调用了 rpop 操作,这代表从列表右侧取出数据。
所以 Request 在列表中的存取顺序是左侧进、右侧出,所以这是有序的进出,即先进先出,英文叫作 First Input First Output,也被简称为 FIFO,而此类的名称就叫作 FifoQueue。
另外还有一个与之相反的实现类,叫作 LifoQueue,实现如下:
class LifoQueue(Base):
"""Per-spider LIFO queue."""
def __len__(self):
"""Return the length of the stack"""
return self.server.llen(self.key)
def push(self, request):
"""Push a request"""
self.server.lpush(self.key, self._encode_request(request))
def pop(self, timeout=0):
"""Pop a request"""
if timeout > 0:
data = self.server.blpop(self.key, timeout)
if isinstance(data, tuple):
data = data[1]
else:
data = self.server.lpop(self.key)
if data:
return self._decode_request(data)
与 FifoQueue 不同的就是它的 pop 方法,在这里使用的是 lpop 操作,也就是从左侧出,而 push 方法依然是使用的 lpush 操作,是从左侧入。那么这样达到的效果就是先进后出、后进先出,英文叫作 Last In First Out,简称为 LIFO,而此类名称就叫作 LifoQueue。同时这个存取方式类似栈的操作,所以其实也可以称作 StackQueue。
另外在源码中还有一个子类实现,叫作 PriorityQueue,顾名思义,它叫作优先级队列,实现如下:
class PriorityQueue(Base):
"""Per-spider priority queue abstraction using redis' sorted set"""
def __len__(self):
"""Return the length of the queue"""
return self.server.zcard(self.key)
def push(self, request):
"""Push a request"""
data = self._encode_request(request)
score = -request.priority
self.server.execute_command('ZADD', self.key, score, data)
def pop(self, timeout=0):
"""
Pop a request
timeout not support in this queue class
"""
pipe = self.server.pipeline()
pipe.multi()
pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)
results, count = pipe.execute()
if results:
return self._decode_request(results[0])
在这里我们可以看到 __len__、push、pop 方法中使用了 server 对象的 zcard、zadd、zrange 操作,可以知道这里使用的存储结果是有序集合 Sorted Set,在这个集合中每个元素都可以设置一个分数,那么这个分数就代表优先级。
在 __len__ 方法里调用了 zcard 操作,返回的就是有序集合的大小,也就是爬取队列的长度,在 push 方法中调用了 zadd 操作,就是向集合中添加元素,这里的分数指定成 Request 的优先级的相反数,因为分数低的会排在集合的前面,所以这里高优先级的 Request 就会存在集合的最前面。pop 方法是首先调用了 zrange 操作取出了集合的第一个元素,因为最高优先级的 Request 会存在集合最前面,所以第一个元素就是最高优先级的 Request,然后再调用 zremrangebyrank 操作将这个元素删除,这样就完成了取出并删除的操作。
此队列是默认使用的队列,也就是爬取队列默认是使用有序集合来存储的。
去重过滤
前面说过 Scrapy 的去重是利用集合来实现的,而在 Scrapy 分布式中的去重就需要利用共享的集合,那么这里使用的就是 Redis 中的集合数据结构。我们来看看去重类是怎样实现的,源码文件是 dupefilter.py,其内实现了一个 RFPDupeFilter 类,如下所示:
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter.
This class can also be used with default Scrapy's scheduler.
"""
logger = logger
def __init__(self, server, key, debug=False):
"""Initialize the duplicates filter.
Parameters
----------
server : redis.StrictRedis
The redis server instance.
key : str
Redis key Where to store fingerprints.
debug : bool, optional
Whether to log filtered requests.
"""
self.server = server
self.key = key
self.debug = debug
self.logdupes = True
@classmethod
def from_settings(cls, settings):
"""Returns an instance from given settings.
This uses by default the key ``dupefilter:<timestamp>``. When using the
``scrapy_redis.scheduler.Scheduler`` class, this method is not used as
it needs to pass the spider name in the key.
Parameters
----------
settings : scrapy.settings.Settings
Returns
-------
RFPDupeFilter
A RFPDupeFilter instance.
"""
server = get_redis_from_settings(settings)
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
"""Returns instance from crawler.
Parameters
----------
crawler : scrapy.crawler.Crawler
Returns
-------
RFPDupeFilter
Instance of RFPDupeFilter.
"""
return cls.from_settings(crawler.settings)
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
fp = self.request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)
def close(self, reason=''):
"""Delete data on close. Called by Scrapy's scheduler.
Parameters
----------
reason : str, optional
"""
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
def log(self, request, spider):
"""Logs given request.
Parameters
----------
request : scrapy.http.Request
spider : scrapy.spiders.Spider
"""
if self.debug:
msg = "Filtered duplicate request: %(request) s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request %(request) s"
"- no more duplicates will be shown"
"(see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
这里同样实现了一个 request_seen 方法,和 Scrapy 中的 request_seen 方法实现极其类似。不过这里集合使用的是 server 对象的 sadd 操作,也就是集合不再是一个简单数据结构了,而是直接换成了数据库的存储方式。
鉴别重复的方式还是使用指纹,指纹同样是依靠 request_fingerprint 方法来获取的。获取指纹之后就直接向集合添加指纹,如果添加成功,说明这个指纹原本不存在于集合中,返回值 1。代码中最后的返回结果是判定添加结果是否为 0,如果刚才的返回值为 1,那这个判定结果就是 False,也就是不重复,否则判定为重复。
这样我们就成功利用 Redis 的集合完成了指纹的记录和重复的验证。
调度器
Scrapy-Redis 还帮我们实现了配合 Queue、DupeFilter 使用的调度器 Scheduler,源文件名称是 scheduler.py。我们可以指定一些配置,如 SCHEDULER_FLUSH_ON_START 即是否在爬取开始的时候清空爬取队列,SCHEDULER_PERSIST 即是否在爬取结束后保持爬取队列不清除。我们可以在 settings.py 里自由配置,而此调度器很好地实现了对接。
接下来我们看看两个核心的存取方法,实现如下所示:
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
def next_request(self):
block_pop_timeout = self.idle_before_close
request = self.queue.pop(block_pop_timeout)
if request and self.stats:
self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider)
return request
enqueue_request 可以向队列中添加 Request,核心操作就是调用 Queue 的 push 操作,还有一些统计和日志操作。next_request 就是从队列中取 Request,核心操作就是调用 Queue 的 pop 操作,此时如果队列中还有 Request,则 Request 会直接取出来,爬取继续,否则如果队列为空,爬取则会重新开始。
总结
那么到现在为止我们就把之前所说的三个分布式的问题解决了,总结如下:
-
爬取队列的实现,在这里提供了三种队列,使用了 Redis 的列表或有序集合来维护。
-
去重的实现,使用了 Redis 的集合来保存 Request 的指纹以提供重复过滤。
-
中断后重新爬取的实现,中断后 Redis 的队列没有清空,再次启动时调度器的 next_request 会从队列中取到下一个 Request,继续爬取。
结语
以上内容便是 Scrapy-Redis 的核心源码解析。Scrapy-Redis 中还提供了 Spider、Item Pipeline 的实现,不过它们并不是必须使用的。
在下一节,我们会将 Scrapy-Redis 集成到之前所实现的 Scrapy 项目中,实现多台主机协同爬取。
实战上手,Scrapy-Redis分布式实现
在前面一节课我们了解了 Scrapy-Redis 的基本原理,本节课我们就结合之前的案例实现基于 Scrapy-Redis 的分布式爬虫吧。
环境准备
本节案例我们基于第 46 讲 —— Scrapy 和 Pyppeteer 的动态渲染页面的抓取案例来进行学习,我们需要把它改写成基于 Redis 的分布式爬虫。
首先我们需要把代码下载下来,其 GitHub 地址为 https://github.com/Python3WebSpider/ScrapyPyppeteer,进入项目,试着运行代码确保可以顺利执行,运行效果如图所示:
其次,我们需要有一个 Redis 数据库,可以直接下载安装包并安装,也可以使用 Docker 启动,保证能正常连接和使用即可,比如我这里就在本地 localhost 启动了一个 Redis 数据库,运行在 6379 端口,密码为空。
另外我们还需要安装 Scrapy-Redis 包,安装命令如下:
pip3 install scrapy-redis
安装完毕之后确保其可以正常导入使用即可。
实现
接下来我们只需要简单的几步操作就可以实现分布式爬虫的配置了。
修改 Scheduler
在前面的课时中我们讲解了 Scheduler 的概念,它是用来处理 Request、Item 等对象的调度逻辑的,默认情况下,Request 的队列是在内存中的,为了实现分布式,我们需要将队列迁移到 Redis 中,这时候我们就需要修改 Scheduler,修改非常简单,只需要在 settings.py 里面添加如下代码即可:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
这里我们将 Scheduler 的类修改为 Scrapy-Redis 提供的 Scheduler 类,这样在我们运行爬虫时,Request 队列就会出现在 Redis 中了。
修改 Redis 连接信息
另外我们还需要修改下 Redis 的连接信息,这样 Scrapy 才能成功连接到 Redis 数据库,修改格式如下:
REDIS_URL = 'redis://[user:pass]@hostname:9001'
在这里我们需要根据如上的格式来修改,由于我的 Redis 是在本地运行的,所以在这里就不需要填写用户名密码了,直接设置为如下内容即可:
REDIS_URL = 'redis://localhost:6379'
修改去重类
既然 Request 队列迁移到了 Redis,那么相应的去重操作我们也需要迁移到 Redis 里面,前一节课我们讲解了 Dupefilter 的原理,这里我们就修改下去重类来实现基于 Redis 的去重:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
配置持久化
一般来说开启了 Redis 分布式队列之后,我们不希望爬虫在关闭时将整个队列和去重信息全部删除,因为很有可能在某个情况下我们会手动关闭爬虫或者爬虫遭遇意外终止,为了解决这个问题,我们可以配置 Redis 队列的持久化,修改如下:
SCHEDULER_PERSIST = True
好了,到此为止我们就完成分布式爬虫的配置了。
运行
上面我们完成的实际上并不是真正意义的分布式爬虫,因为 Redis 队列我们使用的是本地的 Redis,所以多个爬虫需要运行在本地才可以,如果想实现真正意义的分布式爬虫,可以使用远程 Redis,这样我们就能在多台主机运行爬虫连接此 Redis 从而实现真正意义上的分布式爬虫了。
不过没关系,我们可以在本地启动多个爬虫验证下爬取效果。我们在多个命令行窗口运行如下命令:
scrapy crawl book
第一个爬虫出现了如下运行效果:
这时候不要关闭此窗口,再打开另外一个窗口,运行同样的爬取命令:
scrapy crawl book
运行效果如下:
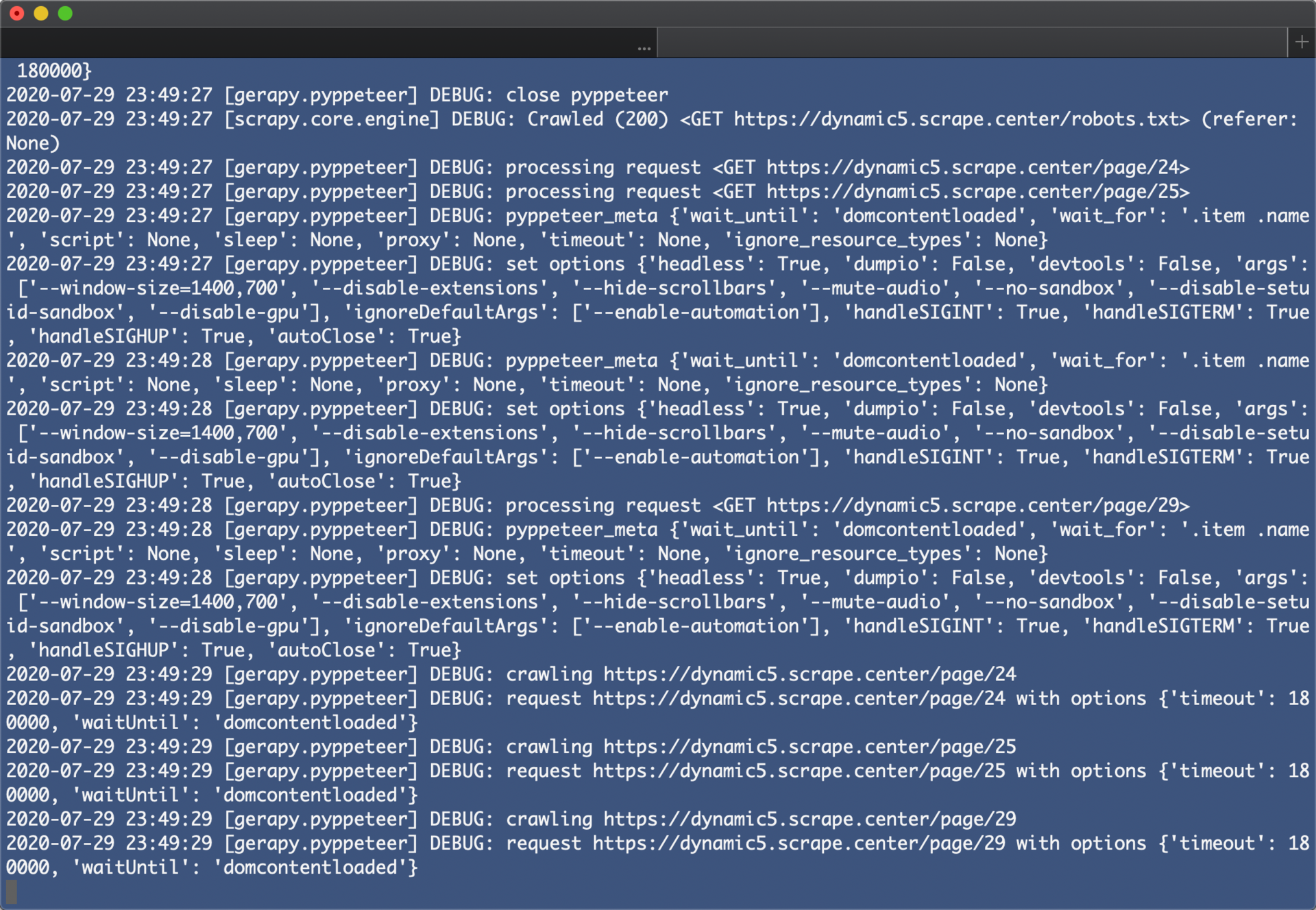
这时候我们可以观察到它从第 24 页开始爬取了,因为当前爬取队列存在第一个爬虫生成的爬取 Request,第二个爬虫启动时检测到有 Request 存在就直接读取已经存在的 Request,然后接着爬取了。
同样,我们可以启动第三个、第四个爬虫实现同样的爬取功能。这样,我们就基于 Scrapy-Redis 成功实现了基本的分布式爬虫功能。
Scrapy部署不用愁,Scrapyd的原理
上节课我们的分布式爬虫部署完成并可以成功运行了,但是有个环节非常烦琐,那就是代码部署。
我们设想下面的几个场景:
-
如果采用上传文件的方式部署代码,我们首先需要将代码压缩,然后采用 SFTP 或 FTP 的方式将文件上传到服务器,之后再连接服务器将文件解压,每个服务器都需要这样配置。
-
如果采用 Git 同步的方式部署代码,我们可以先把代码 Push 到某个 Git 仓库里,然后再远程连接各台主机执行 Pull 操作,同步代码,每个服务器同样需要做一次操作。
如果代码突然有更新,那我们必须更新每个服务器,而且万一哪台主机的版本没控制好,还可能会影响整体的分布式爬取状况。
所以我们需要一个更方便的工具来部署 Scrapy 项目,如果可以省去一遍遍逐个登录服务器部署的操作,那将会方便很多。
本节我们就来看看提供分布式部署的工具 Scrapyd。
了解 Scrapyd
接下来,我们就来深入地了解 Scrapyd,Scrapyd 是一个运行 Scrapy 爬虫的服务程序,它提供一系列 HTTP 接口来帮助我们部署、启动、停止、删除爬虫程序。Scrapyd 支持版本管理,同时还可以管理多个爬虫任务,利用它我们可以非常方便地完成 Scrapy 爬虫项目的部署任务调度。
准备工作
首先我们需要安装 scrapyd,一般我们部署的服务器是 Linux,所以这里以 Linux 为例来进行说明。
这里推荐使用 pip 安装,命令如下:
pip3 install scrapyd
另外为了我们编写的项目能够运行成功,还需要安装项目本身的环境依赖,如上一节的项目需要依赖 Scrapy、Scrapy-Redis、Gerapy-Pyppeteer 等库,也需要在服务器上安装,否则会出现部署失败的问题。
安装完毕之后,需要新建一个配置文件 /etc/scrapyd/scrapyd.conf,Scrapyd 在运行的时候会读取此配置文件。
在 Scrapyd 1.2 版本之后,不会自动创建该文件,需要我们自行添加。首先,执行如下命令新建文件:
sudo mkdir /etc/scrapyd
sudo vi /etc/scrapyd/scrapyd.conf
接着写入如下内容:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
配置文件的内容可以参见官方文档 https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file。这里的配置文件有所修改,其中之一是 max_proc_per_cpu 官方默认为 4,即一台主机每个 CPU 最多运行 4 个 Scrapy 任务,在此提高为 10。另外一个是 bind_address,默认为本地 127.0.0.1,在此修改为 0.0.0.0,以使外网可以访问。
Scrapyd 是一个纯 Python 项目,这里可以直接调用它来运行。为了使程序一直在后台运行,Linux 和 Mac 可以使用如下命令:
(scrapyd > /dev/null &)
这样 Scrapyd 就可以在后台持续运行了,控制台输出直接忽略。当然,如果想记录输出日志,可以修改输出目标,如下所示:
(scrapyd> ~/scrapyd.log &)
此时会将 Scrapyd 的运行结果输出到~/scrapyd.log 文件中。当然也可以使用 screen、tmux、supervisor 等工具来实现进程守护。
安装并运行了 Scrapyd 之后,我们就可以访问服务器的 6800 端口看到一个 WebUI 页面了,例如我的服务器地址为 120.27.34.25,在上面安装好了 Scrapyd 并成功运行,那么我就可以在本地的浏览器中打开: http://120.27.34.25:6800,就可以看到 Scrapyd 的首页,这里请自行替换成你的服务器地址查看即可,如图所示:
如果可以成功访问到此页面,那么证明 Scrapyd 配置就没有问题了。
Scrapyd 的功能
Scrapyd 提供了一系列 HTTP 接口来实现各种操作,在这里我们可以将接口的功能梳理一下,以 Scrapyd 所在的 IP 为 120.27.34.25 为例进行讲解。
daemonstatus.json
这个接口负责查看 Scrapyd 当前服务和任务的状态,我们可以用 curl 命令来请求这个接口,命令如下:
curl http://139.217.26.30:6800/daemonstatus.json
这样我们就会得到如下结果:
{"status": "ok", "finished": 90, "running": 9, "node_name": "datacrawl-vm", "pending": 0}
返回结果是 Json 字符串,status 是当前运行状态, finished 代表当前已经完成的 Scrapy 任务,running 代表正在运行的 Scrapy 任务,pending 代表等待被调度的 Scrapyd 任务,node_name 就是主机的名称。
addversion.json
这个接口主要是用来部署 Scrapy 项目,在部署的时候我们需要首先将项目打包成 Egg 文件,然后传入项目名称和部署版本。
我们可以用如下的方式实现项目部署:
curl http://120.27.34.25:6800/addversion.json -F project=wenbo -F version=first -F [email protected]
在这里 -F 即代表添加一个参数,同时我们还需要将项目打包成 Egg 文件放到本地。
这样发出请求之后我们可以得到如下结果:
{"status": "ok", "spiders": 3}
这个结果表明部署成功,并且其中包含的 Spider 的数量为 3。此方法部署可能比较烦琐,在后面我会介绍更方便的工具来实现项目的部署。
schedule.json
这个接口负责调度已部署好的 Scrapy 项目运行。我们可以通过如下接口实现任务调度:
curl http://120.27.34.25:6800/schedule.json -d project=weibo -d spider=weibocn
在这里需要传入两个参数,project 即 Scrapy 项目名称,spider 即 Spider 名称。返回结果如下:
{"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
status 代表 Scrapy 项目启动情况,jobid 代表当前正在运行的爬取任务代号。
cancel.json
这个接口可以用来取消某个爬取任务,如果这个任务是 pending 状态,那么它将会被移除,如果这个任务是 running 状态,那么它将会被终止。
我们可以用下面的命令来取消任务的运行:
curl http://120.27.34.25:6800/cancel.json -d project=weibo -d job=6487ec79947edab326d6db28a2d86511e8247444
在这里需要传入两个参数,project 即项目名称,job 即爬取任务代号。返回结果如下:
{"status": "ok", "prevstate": "running"}
status 代表请求执行情况,prevstate 代表之前的运行状态。
listprojects.json
这个接口用来列出部署到 Scrapyd 服务上的所有项目描述。我们可以用下面的命令来获取 Scrapyd 服务器上的所有项目描述:
curl http://120.27.34.25:6800/listprojects.json
这里不需要传入任何参数。返回结果如下:
{"status": "ok", "projects": ["weibo", "zhihu"]}
status 代表请求执行情况,projects 是项目名称列表。
listversions.json
这个接口用来获取某个项目的所有版本号,版本号是按序排列的,最后一个条目是最新的版本号。
我们可以用如下命令来获取项目的版本号:
curl http://120.27.34.25:6800/listversions.json?project=weibo
在这里需要一个参数 project,就是项目的名称。返回结果如下:
{"status": "ok", "versions": ["v1", "v2"]}
status 代表请求执行情况,versions 是版本号列表。
listspiders.json
这个接口用来获取某个项目最新的一个版本的所有 Spider 名称。我们可以用如下命令来获取项目的 Spider 名称:
curl http://120.27.34.25:6800/listspiders.json?project=weibo
在这里需要一个参数 project,就是项目的名称。返回结果如下:
{"status": "ok", "spiders": ["weibocn"]}
status 代表请求执行情况,spiders 是 Spider 名称列表。
listjobs.json
这个接口用来获取某个项目当前运行的所有任务详情。我们可以用如下命令来获取所有任务详情:
curl http://120.27.34.25:6800/listjobs.json?project=weibo
在这里需要一个参数 project,就是项目的名称。返回结果如下:
{"status": "ok",
"pending": [{"id": "78391cc0fcaf11e1b0090800272a6d06", "spider": "weibocn"}],
"running": [{"id": "422e608f9f28cef127b3d5ef93fe9399", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664"}],
"finished": [{"id": "2f16646cfcaf11e1b0090800272a6d06", "spider": "weibocn", "start_time": "2017-07-12 10:14:03.594664", "end_time": "2017-07-12 10:24:03.594664"}]}
status 代表请求执行情况,pendings 代表当前正在等待的任务,running 代表当前正在运行的任务,finished 代表已经完成的任务。
delversion.json
这个接口用来删除项目的某个版本。我们可以用如下命令来删除项目版本:
curl http://120.27.34.25:6800/delversion.json -d project=weibo -d version=v1
在这里需要一个参数 project,就是项目的名称,还需要一个参数 version,就是项目的版本。返回结果如下:
{"status": "ok"}
status 代表请求执行情况,这样就代表删除成功了。
delproject.json
这个接口用来删除某个项目。我们可以用如下命令来删除某个项目:
curl http://120.27.34.25:6800/delproject.json -d project=weibo
在这里需要一个参数 project,就是项目的名称。返回结果如下:
{"status": "ok"}
status 代表请求执行情况,这样就代表删除成功了。
以上就是 Scrapyd 所有的接口,我们可以直接请求 HTTP 接口即可控制项目的部署、启动、运行等操作。
ScrapydAPI 的使用
以上的这些接口可能使用起来还不是很方便,没关系,还有一个 ScrapydAPI 库对这些接口又做了一层封装,其安装方式如下:
pip3 install python-scrapyd-api
下面我们来看下 ScrapydAPI 的使用方法,其实核心原理和 HTTP 接口请求方式并无二致,只不过用 Python 封装后使用更加便捷。
我们可以用如下方式建立一个 ScrapydAPI 对象:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://120.27.34.25:6800')
然后就可以通过调用它的方法来实现对应接口的操作了,例如部署的操作可以使用如下方式:
egg = open('weibo.egg', 'rb')
scrapyd.add_version('weibo', 'v1', egg)
这样我们就可以将项目打包为 Egg 文件,然后把本地打包的 Egg 项目部署到远程 Scrapyd 了。
另外 ScrapydAPI 还实现了所有 Scrapyd 提供的 API 接口,名称都是相同的,参数也是相同的。
例如我们可以调用 list_projects 方法即可列出 Scrapyd 中所有已部署的项目:
scrapyd.list_projects()
['weibo', 'zhihu']
另外还有其他的方法在此不再一一列举了,名称和参数都是相同的,更加详细的操作可以参考其官方文档: http://python-scrapyd-api.readthedocs.io/。
我们可以通过它来部署项目,并通过 HTTP 接口来控制任务的运行,不过这里有一个不方便的地方就是部署过程,首先它需要打包 Egg 文件然后再上传,还是比较烦琐的,这里再介绍另外一个工具 Scrapyd-Client。
Scrapyd-Client 部署
Scrapyd-Client 为了方便 Scrapy 项目的部署,提供两个功能:
-
将项目打包成 Egg 文件。
-
将打包生成的 Egg 文件通过 addversion.json 接口部署到 Scrapyd 上。
也就是说,Scrapyd-Client 帮我们把部署全部实现了,我们不需要再去关心 Egg 文件是怎样生成的,也不需要再去读 Egg 文件并请求接口上传了,这一切的操作只需要执行一个命令即可一键部署。
要部署 Scrapy 项目,我们首先需要修改一下项目的配置文件,例如我们之前写的 Scrapy 项目,在项目的第一层会有一个 scrapy.cfg 文件,它的内容如下:
[settings]
default = scrapypyppeteer.settings
[deploy]
#url = http://localhost:6800/
project = scrapypyppeteer
在这里我们需要配置 deploy,例如我们要将项目部署到 120.27.34.25 的 Scrapyd 上,就需要修改为如下内容:
[deploy]
url = http://120.27.34.25:6800/
project = scrapypyppeteer
这样我们再在 scrapy.cfg 文件所在路径执行如下命令:
scrapyd-deploy
运行结果如下:
Packing version 1501682277
Deploying to project "weibo" in http://120.27.34.25:6800/addversion.json
Server response (200):
{"status": "ok", "spiders": 1, "node_name": "datacrawl-vm", "project": "scrapypyppeteer", "version": "1501682277"}
返回这样的结果就代表部署成功了。
我们也可以指定项目版本,如果不指定的话默认为当前时间戳,指定的话通过 version 参数传递即可,例如:
scrapyd-deploy --version 201707131455
值得注意的是在 Python3 的 Scrapyd 1.2.0 版本中我们不要指定版本号为带字母的字符串,需要为纯数字,否则可能会出现报错。
另外如果我们有多台主机,我们可以配置各台主机的别名,例如可以修改配置文件为:
[deploy:vm1]
url = http://120.27.34.24:6800/
project = scrapypyppeteer
[deploy:vm2]
url = http://139.217.26.30:6800/
project = scrapypyppeteer
有多台主机的话就在此统一配置,一台主机对应一组配置,在 deploy 后面加上主机的别名即可,这样如果我们想将项目部署到 IP 为 139.217.26.30 的 vm2 主机,我们只需要执行如下命令:
scrapyd-deploy vm2
这样我们就可以将项目部署到名称为 vm2 的主机上了。
如此一来,如果我们有多台主机,我们只需要在 scrapy.cfg 文件中配置好各台主机的 Scrapyd 地址,然后调用 scrapyd-deploy 命令加主机名称即可实现部署,非常方便。
如果 Scrapyd 设置了访问限制的话,我们可以在配置文件中加入用户名和密码的配置,同时修改端口,修改成 Nginx 代理端口,如在模块一我们使用的是 6801,那么这里就需要改成 6801,修改如下:
[deploy:vm1]
url = http://120.27.34.24:6801/
project = scrapypyppeteer
username = admin
password = admin
[deploy:vm2]
url = http://139.217.26.30:6801/
project = scrapypyppeteer
username = germey
password = germey
这样通过加入 username 和 password 字段,我们就可以在部署时自动进行 Auth 验证,然后成功实现部署。
总结
以上我们介绍了 Scrapyd、Scrapyd-API、Scrapyd-Client 的部署方式,希望你可以多多尝试。
容器化技术也得会,Scrapy对接docker
上一节课我们学习了 Scrapy 和 Scrapyd 的用法,虽然它们可以解决项目部署的一些问题,但其实这种方案并没有真正彻底解决环境配置的问题。
比如使用 Scrapyd 时我们依然需要安装对应的依赖库,即使这样仍免不了还是会出现环境冲突和不一致的问题。因此,本节课我会再介绍另一种部署方案 —— Docker。
Docker 可以提供操作系统级别的虚拟环境,一个 Docker 镜像一般都会包含一个完整的操作系统,而这些系统内也有已经配置好的开发环境,如 Python 3.6 环境等。
我们可以直接使用此 Docker 的 Python 3 镜像运行一个容器,将项目直接放到容器里运行,就不用再额外配置 Python 3 环境了,这样就解决了环境配置的问题。
我们也可以进一步将 Scrapy 项目制作成一个新的 Docker 镜像,镜像里只包含适用于本项目的 Python 环境。如果要部署到其他平台,只需要下载该镜像并运行就好了,因为 Docker 运行时采用虚拟环境,和宿主机是完全隔离的,所以也不需要担心环境冲突问题。
如果我们能够把 Scrapy 项目制作成一个 Docker 镜像,只要其他主机安装了 Docker,那么只要将镜像下载并运行即可,而不必再担心环境配置问题或版本冲突问题。
因此,利用 Docker 我们就能很好地解决环境配置、环境冲突等问题。接下来,我们就尝试把一个 Scrapy 项目制作成一个 Docker 镜像。
本节目标
我们要实现把前文 Scrapy 的入门项目打包成一个 Docker 镜像的过程。项目爬取的网址为: http://quotes.toscrape.com/,本模块 Scrapy 入门一节已经实现了 Scrapy 对此站点的爬取过程,项目代码为: https://github.com/Python3WebSpider/ScrapyTutorial,如果本地不存在的话可以 Clone 下来。
准备工作
请确保已经安装好 Docker 并可以正常运行,如果没有安装可以参考 https://cuiqingcai.com/5438.html。
创建 Dockerfile
首先在项目的根目录下新建一个 requirements.txt 文件,将整个项目依赖的 Python 环境包都列出来,如下所示:
scrapy
pymongo
如果库需要特定的版本,我们还可以指定版本号,如下所示:
scrapy>=1.4.0
pymongo>=3.4.0
在项目根目录下新建一个 Dockerfile 文件,文件不加任何后缀名,修改内容如下所示:
FROM python:3.7
ENV PATH /usr/local/bin:$PATH
ADD . /code
WORKDIR /code
RUN pip3 install -r requirements.txt
CMD scrapy crawl quotes
第一行的 FROM 代表使用的 Docker 基础镜像,在这里我们直接使用 python:3.7 的镜像,在此基础上运行 Scrapy 项目。
第二行 ENV 是环境变量设置,将 /usr/local/bin:$PATH 赋值给 PATH,即增加 /usr/local/bin 这个环境的变量路径。
第三行 ADD 是将本地的代码放置到虚拟容器中。它有两个参数:第一个参数是“.”,代表本地当前路径;第二个参数是 /code,代表虚拟容器中的路径,也就是将本地项目所有内容放置到虚拟容器的 /code 目录下,以便于在虚拟容器中运行代码。
第四行 WORKDIR 是指定工作目录,这里将刚才添加的代码路径设置成工作路径。在这个路径下的目录结构和当前本地目录结构是相同的,所以我们可以直接执行库安装命令、爬虫运行命令等。
第五行 RUN 是执行某些命令来做一些环境准备工作。由于 Docker 虚拟容器内只有 Python 3 环境,而没有所需要的 Python 库,所以我们运行此命令在虚拟容器中安装相应的 Python 库如 Scrapy,这样就可以在虚拟容器中执行 Scrapy 命令了。
第六行 CMD 是容器启动命令。在容器运行时,此命令会被执行。在这里我们直接用 scrapy crawl quotes 来启动爬虫。
修改 MongoDB 连接
接下来我们需要修改 MongoDB 的连接信息。如果我们继续用 localhost 是无法找到 MongoDB 的,因为在 Docker 虚拟容器里 localhost 实际指向容器本身的运行 IP,而容器内部并没有安装 MongoDB,所以爬虫无法连接 MongoDB。
这里的 MongoDB 地址可以有如下两种选择。
-
如果只想在本机测试,我们可以将地址修改为宿主机的 IP,也就是容器外部的本机 IP,一般是一个局域网 IP,使用 ifconfig 命令即可查看。
-
如果要部署到远程主机运行,一般 MongoDB 都是可公网访问的地址,修改为此地址即可。
但为了保证灵活性,我们可以将这个连接字符串通过环境变量传递进来,比如修改为:
import os
MONGO_URI = os.getenv('MONGO_URI')
MONGO_DB = os.getenv('MONGO_DB', 'tutorial')
这样项目的配置就完成了。
构建镜像
接下来,我们便可以构建镜像了,执行如下命令:
docker build -t quotes:latest .
这样输出就说明镜像构建成功。这时我们查看一下构建的镜像,如下所示:
Sending build context to Docker daemon 191.5 kB
Step 1/6 : FROM python:3.7
---> 968120d8cbe8
Step 2/6 : ENV PATH /usr/local/bin:$PATH
---> Using cache
---> 387abbba1189
Step 3/6 : ADD . /code
---> a844ee0db9c6
Removing intermediate container 4dc41779c573
Step 4/6 : WORKDIR /code
---> 619b2c064ae9
Removing intermediate container bcd7cd7f7337
Step 5/6 : RUN pip3 install -r requirements.txt
---> Running in 9452c83a12c5
...
Removing intermediate container 9452c83a12c5
Step 6/6 : CMD scrapy crawl quotes
---> Running in c092b5557ab8
---> c8101aca6e2a
Removing intermediate container c092b5557ab8
Successfully built c8101aca6e2a
出现类似输出就证明镜像构建成功了,这时执行,比如我们查看一下构建的镜像:
docker images
返回结果中其中有一行就是:
quotes latest 41c8499ce210 2 minutes ago 769 MB
这就是我们新构建的镜像。
运行
我们可以先在本地测试运行,这时候我们需要指定 MongoDB 的连接信息,比如我在宿主机上启动了一个 MongoDB,找到当前宿主机的 IP 为 192.168.3.47,那么这里我就可以指定 MONGO_URI 并启动 Docker 镜像:
docker run -e MONGO_URI=192.168.3.47 quotes
当然我们还可以指定 MONGO_URI 为远程 MongoDB 连接字符串。
另外我们也可以利用 Docker-Compose 来启动,与此同时顺便也可以使用 Docker 来新建一个 MongoDB。可以在项目目录下新建 docker-compose.yaml 文件,如下所示:
version: '3'
services:
crawler:
build: .
image: quotes
depends_on:
- mongo
environment:
MONGO_URI: mongo:7017
mongo:
image: mongo
ports:
- 7017:27017
这里我们使用 Docker-Compose 配置了两个容器,二者需要配合启动。
首先是 crawler 这个容器,其 build 路径是当前路径,image 代表 build 生成的镜像名称,这里取名为 quotes,depends_on 代表容器的启动依赖顺序,这里依赖于 mongo 这个容器,environment 这里就是指定容器运行时的环境变量,这里指定为 mongo:7017 。
另外一个容器就是刚才的 crawler 这个容器所依赖的 MongoDB 数据库了,在这里我们直接指定了镜像为 mongo,运行端口配置为 7017:27017 ,这代表容器内的 MongoDB 运行在 27017 端口上,这个端口会映射到宿主机的 7017 端口上,所以我们在宿主机通过 7017 端口就能连接到这个 MongoDB 数据库。
好,这时候我们运行一下:
docker-compose up
然后 Docker 会构建镜像并运行,运行结果如下:
Starting scrapytutorial_mongo_1 ... done
Recreating scrapytutorial_crawler_1 ... done
Attaching to scrapytutorial_mongo_1, scrapytutorial_crawler_1
mongo_1 | {"t":{"$date":"2020-08-06T16:18:05.310+00:00"},"s":"I", "c":"CONTROL", "id":23285, "ctx":"main","msg":"Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none'"}
mongo_1 | {"t":{"$date":"2020-08-06T16:18:05.312+00:00"},"s":"W", "c":"ASIO", "id":22601, "ctx":"main","msg":"No TransportLayer configured during NetworkInterface startup"}
mongo_1 | {"t":{"$date":"2020-08-06T16:18:05.312+00:00"},"s":"I", "c":"NETWORK", "id":4648601, "ctx":"main","msg":"Implicit TCP FastOpen unavailable. If TCP FastOpen is required, set tcpFastOpenServer, tcpFastOpenClient, and tcpFastOpenQueueSize."}
...
crawler_1 | 2020-08-06 16:18:06 [scrapy.utils.log] INFO: Scrapy 2.3.0 started (bot: tutorial)
crawler_1 | 2020-08-06 16:18:06 [scrapy.utils.log] INFO: Versions: lxml 4.5.2.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.7.8 (default, Jun 30 2020, 18:27:23) - [GCC 8.3.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1g 21 Apr 2020), cryptography 3.0, Platform Linux-4.19.76-linuxkit-x86_64-with-debian-10.4
crawler_1 | 2020-08-06 16:18:06 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor
crawler_1 | 2020-08-06 16:18:06 [scrapy.crawler] INFO: Overridden settings:
crawler_1 | {'BOT_NAME': 'tutorial',
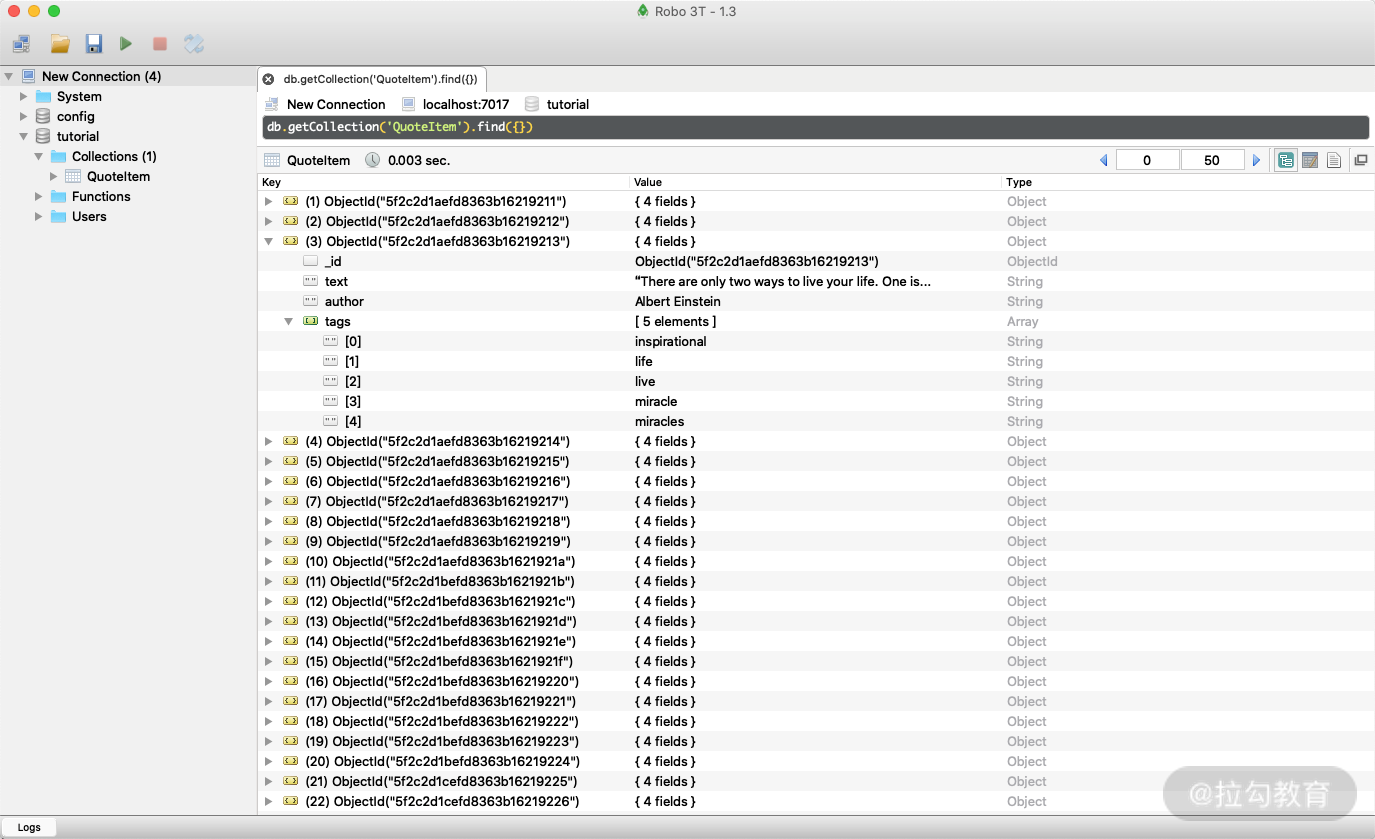
这时候就发现爬虫已经正常运行了,同时我们在宿主机上连接 localhost:7017 这个 MongoDB 服务就能看到爬取的结果了:
这就是用 Docker-Compose 启动的方式,其启动更加便捷,参数可以配置到 Docker-Compose 文件中。
推送至 Docker Hub
构建完成之后,我们可以将镜像 Push 到 Docker 镜像托管平台,如 Docker Hub 或者私有的 Docker Registry 等,这样我们就可以从远程服务器下拉镜像并运行了。
以 Docker Hub 为例,如果项目包含一些私有的连接信息(如数据库),我们最好将 Repository 设为私有或者直接放到私有的 Docker Registry 中。
首先在 https://hub.docker.com注册一个账号,新建一个 Repository,名为 quotes。比如,我的用户名为 germey,新建的 Repository 名为 quotes,那么此 Repository 的地址就可以用 germey/quotes 来表示,当然你也可以自行修改。
为新建的镜像打一个标签,命令如下所示:
docker tag quotes:latest germey/quotes:latest
推送镜像到 Docker Hub 即可,命令如下所示:
docker push germey/quotes
Docker Hub 中便会出现新推送的 Docker 镜像了,如图所示。
如果我们想在其他的主机上运行这个镜像,在主机上装好 Docker 后,可以直接执行如下命令:
docker run germey/quotes
这样就会自动下载镜像,然后启动容器运行,不需要配置 Python 环境,不需要关心版本冲突问题。
当然我们也可以使用 Docker-Compose 来构建镜像和推送镜像,这里我们只需要修改 docker-compose.yaml 文件即可:
version: '3'
services:
crawler:
build: .
image: germey/quotes
depends_on:
- mongo
environment:
MONGO_URI: mongo:7017
mongo:
image: mongo
ports:
- 7017:27017
可以看到,这里我们就将 crawler 的 image 内容修改为了 germey/quotes ,接下来执行:
docker-compose build
docker-compose push
就可以把镜像推送到 Docker Hub 了。
结语
本课时,我们讲解了将 Scrapy 项目制作成 Docker 镜像并部署到远程服务器运行的过程。使用此种方式,我们在本节课开始时所列出的问题都可以迎刃而解了。
Scrapy对接Kubernetes并实现定时爬取
在上一节我们了解了如何制作一个 Scrapy 的 Docker 镜像,本节课我们来介绍下如何将镜像部署到 Kubernetes 上。
Kubernetes
Kubernetes 是谷歌开发的,用于自动部署,扩展和管理容器化应用程序的开源系统,其稳定性高、扩展性好,功能十分强大。现在业界已经越来越多地采用 Kubernetes 来部署和管理各个项目,
如果你还不了解 Kubernetes,可以参考其官方文档来学习一下: https://kubernetes.io/。
准备工作
如果我们需要将上一节的镜像部署到 Kubernetes 上,则首先需要我们有一个 Kubernetes 集群,同时需要能使用 kubectl 命令。
Kubernetes 集群可以自行配置,也可以使用各种云服务提供的集群,如阿里云、腾讯云、Azure 等,另外还可以使用 Minikube 等来快速搭建,当然也可以使用 Docker 本身提供的 Kubernetes 服务。
比如我这里就直接使用了 Docker Desktop 提供的 Kubernetes 服务,勾选 Enable 直接开启即可。
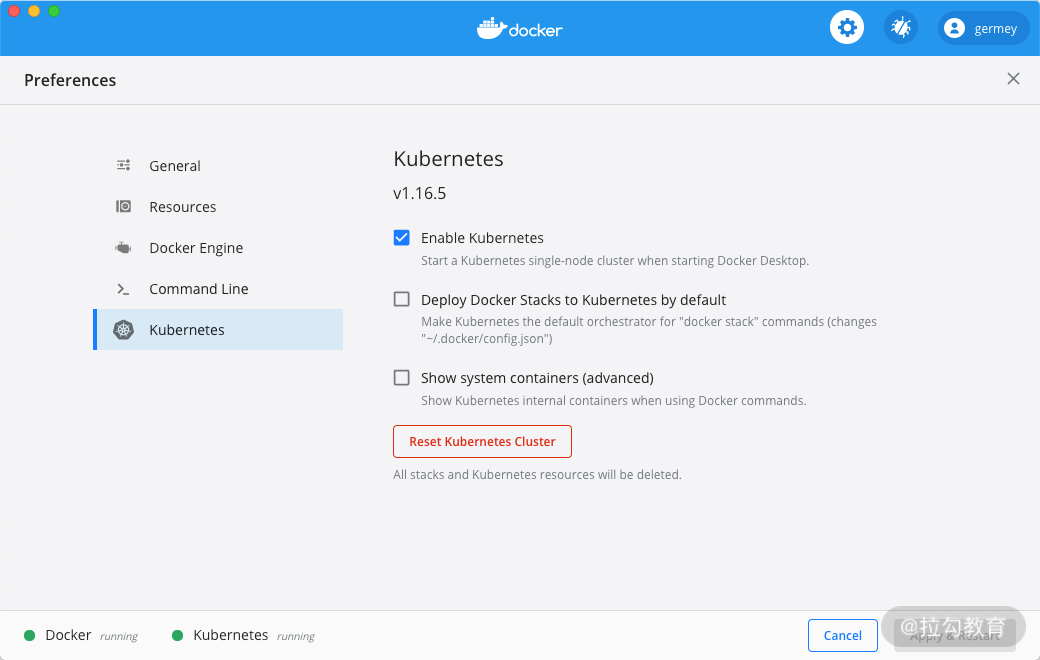
kubectl 是用来操作 Kubernetes 的命令行工具,可以参考 https://kubernetes.io/zh/docs/tasks/tools/install-kubectl/ 来安装。
如果以上都安装好了,可以运行下 kubectl 命令验证下能否正常获取节点信息:
kubectl get nodes
运行结果类似如下:
NAME STATUS ROLES AGE VERSION
docker-desktop Ready master 75d v1.16.6-beta.0
部署
要部署的话我们需要先创建一个命名空间 Namespace,这里直接使用 kubectl 命令创建即可,Namespace 的名称这里我们取名为 crawler。
创建命令如下:
kubectl create namespace crawler
运行结果如下:
namespace/crawler created
如果出现上述结果就说明命名空间创建成功了。接下来我们就需要把 Docker 镜像部署到这个 Namespace 下面了。
Kubernetes 里面的资源是用 yaml 文件来定义的,如果要部署一次性任务或者为我们提供服务可以使用 Deployment,更多详情可以参考 Kubernetes 对于 Deployment 的说明: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/。
新建 deployment.yaml 文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: crawler-quotes
namespace: crawler
labels:
app: crawler-quotes
spec:
replicas: 1
selector:
matchLabels:
app: crawler-quotes
template:
metadata:
labels:
app: crawler-quotes
spec:
containers:
- name: crawler-quotes
image: germey/quotes
env:
- name: MONGO_URI
value: <mongo>
这里我们就可以按照 Deployment 的规范声明一个 yaml 文件了,指定 namespace 为 crawler,并指定 container 的 image 为我们已经 Push 到 Docker Hub 的镜像 germey/quotes,另外通过 env 指定了环境变量,注意这里需要将 <mongo> 替换成一个有效的 MongoDB 连接字符串,如一个远程 MongoDB 服务。
接下来我们只需要使用 kubectl 命令即可应用该部署:
kubectl apply -f deployment.yaml
运行完毕之后会提示类似如下结果:
deployment.apps/crawler-quotes created
这样就说明部署成功了。如果 MongoDB 服务能够正常连接的话,这个爬虫就会运行并将结果存储到 MongoDB 中。
另外我们还可以通过命令行或者 Kubernetes 的 Dashboard 查看部署任务的运行状态。
如果我们想爬虫定时运行的话,可以借助于 Kubernetes 提供的 cronjob 来将爬虫配置为定时任务,其运行模式就类似于 crontab 命令一样,详细用法可以参考: https://kubernetes.io/zh/docs/tasks/job/automated-tasks-with-cron-jobs/。
可以新建 cronjob.yaml,内容如下:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: crawler-quotes
namespace: crawler
spec:
schedule: "0 */1 * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: crawler-quotes
image: germey/quotes
env:
- name: MONGO_URI
value: <mongo>
注意到这里 kind 我们不再使用 Deployment,而是改成了 CronJob,代表定时任务。 spec.schedule 里面定义了 crontab 格式的定时任务配置,这里代表每小时运行一次。其他的配置基本一致,同样注意这里需要将 <mongo> 替换成一个有效的 MongoDB 连接字符串,如一个远程 MongoDB 服务。
接下来我们只需要使用 kubectl 命令即可应用该部署:
kubectl apply -f cronjob.yaml
运行完毕之后会提示类似如下结果:
cronjob.batch/crawler-quotes created
出现这样的结果这就说明部署成功了,这样这个爬虫就会每小时运行一次,并将数据存储到指定的 MongoDB 数据库中。
总结
以上我们就简单介绍了下 Kubernetes 部署爬虫的基本操作,Kubernetes 非常复杂,需要学习的内容很多,我们这一节介绍的只是冰山一角,还有更多的内容等待你去探索。
从爬虫小白到高手的必经之路
如果你看到了本课时,那么恭喜你已经学完了本专栏课程的所有内容,爬虫的知识点很复杂,一路学过来相信你也经历了不少坎坷。
本节课我们对网络爬虫所要学习的内容做一次总结,这里面也是我个人认为爬虫工程师应该具备的一些技术栈,由于专栏篇幅有限,肯定不可能把所有的知识点都覆盖到,但基础知识都已经涵盖了,下面我会把网络爬虫的知识点进行总结和梳理,如果你想深入学习网络爬虫的话可以参考。
网络爬虫的学习关系到计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习、数据分析等各个方向的内容,它像一张大网一样把现在一些主流的技术栈都连接在了一起。正因为涵盖的方向多,因此学习的东西也非常零散和杂乱。
初学爬虫
一些最基本的网站,往往不带任何反爬措施。比如某个博客站点,我们要爬全站的话就顺着列表页爬到文章页,再把文章的时间、作者、正文等信息爬下来就可以了。
那代码怎么写呢?用 Python 的 requests 等库就够了,写一个基本的逻辑,顺带把一篇篇文章的源码获取下来,解析的话用 XPath、BeautifulSoup、PyQuery 或者正则表达式,或者粗暴的字符串匹配把想要的内容抠出来,再加个文本写入存下来就可以了。
代码也很简单,就只是几个方法的调用。逻辑也很简单,几个循环加存储。最后就能看到一篇篇文章被我们存到了自己的电脑里。当然如果你不太会写代码或者都懒得写,那么利用基本的可视化爬取工具,如某爪鱼、某裔采集器也能通过可视化点选的方式把数据爬下来。
如果存储方面稍微扩展一下的话,可以对接上 MySQL、MongoDB、Elasticsearch、Kafka 等来保存数据,实现持久化存储。以后查询或者操作会更方便。
反正,不管效率如何,一个完全没有反爬的网站用最基本的方式就可以搞定。到这里,你可以说自己会爬虫了吗?不,还差得远呢。
Ajax、动态渲染
随着互联网的发展,前端技术也在不断变化,数据的加载方式也不再是单纯的服务端渲染了。现在你可以看到很多网站的数据可能都是通过接口的形式传输的,或者即使不是接口那也是一些 JSON 数据,然后经过 JavaScript 渲染得出来的。
这时候,你要再用 requests 来爬取就不行了,因为 requests 爬下来的源码是服务端渲染得到的,浏览器看到页面的和 requests 获取的结果是不一样的。真正的数据是经过 JavaScript 执行得出来的,数据来源可能是 Ajax,也可能是页面里的某些 Data,也可能是一些 ifame 页面等,不过大多数情况下可能是 Ajax 接口获取的。
所以很多情况下需要分析 Ajax,知道这些接口的调用方式之后再用程序来模拟。但是有些接口带着加密参数,比如 token、sign 等,又不好模拟,怎么办呢?
一种方法就是去分析网站的 JavaScript 逻辑,死抠里面的代码,研究这些参数是怎么构造的,找出思路之后再用爬虫模拟或重写就行了。如果你解析出来了,那么直接模拟的方式效率会高很多,这里面就需要一些 JavaScript 基础了,当然有些网站加密逻辑做得太厉害了,你可能花一个星期也解析不出来,最后只能放弃了。
那这样解不出来或者不想解了,该怎么办呢?这时候可以用一种简单粗暴的方法,也就是直接用模拟浏览器的方式来爬取,比如用 Puppeteer、Pyppeteer、Selenium、Splash 等,这样爬取到的源代码就是真正的网页代码,数据自然就好提取了,同时也就绕过分析 Ajax 和一些 JavaScript 逻辑的过程。这种方式就做到了可见即可爬,难度也不大,同时模拟了浏览器,也不太会有一些法律方面的问题。
但其实后面的这种方法也会遇到各种反爬的情况,现在很多网站都会去识别 webdriver,看到你是用的 Selenium 等工具,直接拒接或不返回数据,所以你碰到这种网站还得专门来解决这个问题。
多进程、多线程、协程
上面的情况如果用单线程的爬虫来模拟是比较简单的,但是有个问题就是速度慢啊。
爬虫是 I/O 密集型的任务,所以可能大多数情况下都在等待网络的响应,如果网络响应速度慢,那就得一直等着。但这个空余的时间其实可以让 CPU 去做更多事情。那怎么办呢?多开一些线程吧。
所以这个时候我们就可以在某些场景下加上多进程、多线程,虽然说多线程有 GIL 锁,但对于爬虫来说其实影响没那么大,所以用上多进程、多线程都可以成倍地提高爬取速度,对应的库就有 threading、multiprocessing 等。
异步协程就更厉害了,用 aiohttp、gevent、tornado 等工具,基本上想开多少并发就开多少并发,但是还是得谨慎一些,别把目标网站搞挂了。
总之,用上这几个工具,爬取速度就提上来了。但速度提上来了不一定都是好事,反爬措施接着肯定就要来了,封你 IP、封你账号、弹验证码、返回假数据,所以有时候龟速爬似乎也是个解决办法?
分布式
多线程、多进程、协程都能加速,但终究还是单机的爬虫。要真正做到规模化,还得靠分布式爬虫来搞定。
分布式的核心是什么?资源共享。比如爬取队列共享、去重指纹共享,等等。
我们可以使用一些基础的队列或组件来实现分布式,比如 RabbitMQ、Celery、Kafka、Redis 等,但经过很多人的尝试,自己去实现一个分布式爬虫,性能和扩展性总会出现一些问题。不少企业内部其实也有自己开发的一套分布式爬虫,和业务更紧密,这种当然是最好了。
现在主流的 Python 分布式爬虫还是基于 Scrapy 的,对接 Scrapy-Redis、Scrapy-Redis-BloomFilter 或者使用 Scrapy-Cluster 等,它们都是基于 Redis 来共享爬取队列的,多多少少总会遇到一些内存的问题。所以一些人也考虑对接到其他的消息队列上面,比如 RabbitMQ、Kafka 等,可以解决一些问题,效率也不差。
总之,要提高爬取效率,分布式还是必须要掌握的。
验证码
爬虫时难免遇到反爬,验证码就是其中之一。要会反爬,那首先就要会解验证码。
现在你可以看到很多网站都会有各种各样的验证码,比如最简单的图形验证码,要是验证码的文字规则的话,OCR 检测或基本的模型库都能识别,你可以直接对接一个打码平台来解决,准确率还是可以的。
然而现在你可能都见不到什么图形验证码了,都是一些行为验证码,如某验、某盾等,国外也有很多,比如 reCaptcha 等。一些稍微简单一点的,比如滑动的,你可以想办法识别缺口,比如图像处理比对、深度学习识别都是可以的。
对于轨迹行为你可以自己写一个模拟正常人行为的,加入抖动等。有了轨迹之后如何模拟呢,如果你非常厉害,那么可以直接去分析验证码的 JavaScript 逻辑,把轨迹数据录入,就能得到里面的一些加密参数,直接将这些参数放到表单或接口里面就能直接用了。当然也可以用模拟浏览器的方式来拖动,也能通过一定的方式拿到加密参数,或者直接用模拟浏览器的方式把登录一起做了,拿着 Cookies 来爬也行。
当然拖动只是一种验证码,还有文字点选、逻辑推理等,要是真不想自己解决,可以找打码平台来解析出来再模拟,但毕竟是花钱的,一些高手就会选择自己训练深度学习相关的模型,收集数据、标注、训练,针对不同的业务训练不同的模型。这样有了核心技术,也不用再去花钱找打码平台了,再研究下验证码的逻辑模拟一下,加密参数就能解析出来了。不过有的验证码解析非常难,以至于我也搞不定。
当然有些验证码可能是请求过于频繁而弹出来的,这种如果换 IP 也能解决。
封 IP
封 IP 也是一件令人头疼的事,行之有效的方法就是换代理了。代理有很多种,市面上免费的,收费的太多太多了。
首先可以把市面上免费的代理用起来,自己搭建一个代理池,收集现在全网所有的免费代理,然后加一个测试器一直不断测试,测试的网址可以改成你要爬的网址。这样测试通过的一般都能直接拿来爬取目标网站。我自己也搭建过一个代理池,现在对接了一些免费代理,定时爬、定时测,还写了个 API 来取,放在了 GitHub 上: https://github.com/Python3WebSpider/ProxyPool,打好了 Docker 镜像,提供了 Kubernetes 脚本,你可以直接拿来用。
付费代理也是一样,很多商家提供了代理提取接口,请求一下就能获取几十几百个代理,我们可以同样把它们接入到代理池里面。但这个代理服务也分各种套餐,什么开放代理、独享代理等的质量和被封的概率也是不一样的。
有的商家还利用隧道技术搭建了代理,这样代理的地址和端口我们是不知道的,代理池是由他们来维护的,比如某布云,这样用起来更省心一些,但是可控性就差一些。
还有更稳定的代理,比如拨号代理、蜂窝代理等,接入成本会高一些,但是一定程度上也能解决一些封 IP 的问题。
封账号
有些信息需要模拟登录才能爬取,如果爬得过快,目标网站直接把你的账号封禁了,就没办法了。比如爬公众号的,人家把你 WX 号封了,那就全完了。
一种解决方法就是放慢频率,控制节奏。还有一种方法就是看看别的终端,比如手机页、App 页、wap 页,看看有没有能绕过登录的方法。
另外比较好的方法,就是分流。如果你的号足够多,建一个池子,比如 Cookies 池、Token 池、Sign 池等,多个账号跑出来的 Cookies、Token 都放到这个池子里,用的时候随机从里面获取一个。如果你想保证爬取效率不变,那么 100 个账号相比 20 个账号,对于每个账号对应的 Cookies、Token 的取用频率就变成原来的了 1/5,那么被封的概率也就随之降低了。
奇葩的反爬
上面说的是几种比较主流的反爬方式,当然还有非常多奇葩的反爬。比如返回假数据、返回图片化数据、返回乱序数据,等等,那都需要具体情况具体分析。
这些反爬也得小心点,之前见过一个反爬直接返回 rm -rf / 的也不是没有,你要是正好有个脚本模拟执行返回结果,后果自己想象。
JavaScript 逆向
说到重点了。随着前端技术的进步和网站反爬意识的增强,很多网站选择在前端上下功夫,那就是在前端对一些逻辑或代码进行加密或混淆。当然这不仅仅是为了保护前端的代码不被轻易盗取,更重要的是反爬。比如很多 Ajax 接口都会带着一些参数,比如 sign、token 等,这些前文也讲过了。这种数据我们可以用前文所说的 Selenium 等方式来爬取,但总归来说效率太低了,毕竟它模拟的是网页渲染的整个过程,而真实的数据可能仅仅就藏在一个小接口里。
如果我们能够找出一些接口参数的真正逻辑,用代码来模拟执行,那效率就会有成倍的提升,而且还能在一定程度上规避上述的反爬现象。但问题是什么?比较难实现啊。
Webpack 是一方面,前端代码都被压缩和转码成一些 bundle 文件,一些变量的含义已经丢失,不好还原。然后一些网站再加上一些 obfuscator 的机制,把前端代码变成你完全看不懂的东西,比如字符串拆散打乱、变量十六进制化、控制流扁平化、无限 debug、控制台禁用等,前端的代码和逻辑已经面目全非。有的用 WebAssembly 等技术把前端核心逻辑直接编译,那就只能慢慢抠了,虽然说有些有一定的技巧,但是总归来说还是会花费很多时间。但一旦解析出来了,那就万事大吉了。
很多公司招聘爬虫工程师都会问有没有 JavaScript 逆向基础,破解过哪些网站,比如某宝、某多、某条等,解出来某个他们需要的可能就直接录用你。每家网站的逻辑都不一样,难度也不一样。
App
当然爬虫不仅仅是网页爬虫了,随着互联网时代的发展,现在越来越多的公司都选择将数据放到 App 上,甚至有些公司只有 App 没有网站。所以数据只能通过 App 来爬。
怎么爬呢?基本的就是抓包工具了,Charles、Fiddler 等抓到接口之后,直接拿来模拟就行了。
如果接口有加密参数怎么办呢?一种方法你可以边爬边处理,比如 mitmproxy 直接监听接口数据。另一方面你可以走 Hook,比如上 Xposed 也可以拿到。
那爬的时候又怎么实现自动化呢?总不能拿手来戳吧。其实工具也多,安卓原生的 adb 工具也行,Appium 现在已经是比较主流的方案了,当然还有其他的某精灵都是可以实现的。
最后,有的时候可能真的就不想走自动化的流程,我就想把里面的一些接口逻辑抠出来,那就需要搞逆向了,IDA Pro、jdax、FRIDA 等工具就派上用场了,当然这个过程和 JavaScript 逆向一样很痛苦,甚至可能得读汇编指令。
智能化
上面的这些知识,都掌握了以后,恭喜你已经超过了百分之八九十的爬虫玩家了,当然专门搞 JavaScript 逆向、App 逆向的都是站在食物链顶端的人,这种严格来说已经不算爬虫范畴了。
除了上面的技能,在一些场合下,我们可能还需要结合一些机器学习的技术,让我们的爬虫变得更智能起来。
比如现在很多博客、新闻文章,其页面结构相似度比较高,要提取的信息也比较类似。
比如如何区分一个页面是索引页还是详情页?如何提取详情页的文章链接?如何解析文章页的页面内容?这些其实都是可以通过一些算法来计算出来的。
所以,一些智能解析技术也应运而生,比如提取详情页,我的一位朋友写的 GeneralNewsExtractor 表现就非常好。
假如说有一个需求,需要爬取一万个新闻网站数据,要一个个写 XPath 吗?如果有了智能化解析技术,在容忍一定错误的条件下,完成这个就是分分钟的事情。
总之,如果我们能把这一块也学会了,我们的爬虫技术就会如虎添翼。
运维
这块内容也是一个重头戏。爬虫和运维也是息息相关的。比如:
-
写完一个爬虫,怎样去快速部署到 100 台主机上运行起来。
-
怎么灵活地监控每个爬虫的运行状态。
-
爬虫有处代码改动,如何去快速更新。
-
怎样监控一些爬虫的占用内存、消耗的 CPU 状况。
-
怎样科学地控制爬虫的定时运行。
-
爬虫出现了问题,怎样能及时收到通知,怎样设置科学的报警机制。
这里面,部署大家各有各的方法,比如可以用 Ansible。如果用 Scrapy 的话有 Scrapyd,然后配合上一些管理工具也能完成一些监控和定时任务。不过我现在用的更多的还是 Docker + Kubernetes,再加上 DevOps 一套解决方案,比如 GitHub Actions、Azure Pipelines、Jenkins 等,快速实现分发和部署。
定时任务大家有的用 crontab,有的用 apscheduler,有的用管理工具,有的用 Kubernetes,我的话用 Kubernetes 会多一些了,定时任务也很好实现。
至于监控的话,也有很多,专门的爬虫管理工具自带了一些监控和报警功能。一些云服务也带了一些监控的功能。我用的是 Kubernetes + Prometheus + Grafana,什么 CPU、内存、运行状态,一目了然,报警机制在 Grafana 里面配置也很方便,支持 Webhook、邮件甚至某钉。
数据的存储和监控,用 Kafka、Elasticsearch 个人感觉也挺方便的,我主要用的是后者,然后再和 Grafana 配合起来,数据爬取量、爬取速度等等监控也都一目了然。
法律
另外希望你在做网络爬虫的过程中注意一些法律问题,基本上就是:
-
不要碰个人隐私信息。
-
规避商业竞争,看清目标站点的法律条款限制。
-
限制并发速度,不要影响目标站点的正常运行。
-
不要碰黑产、黄赌毒。
-
不随便宣传和传播目标站点或 App 的破解方案。
-
非公开数据一定要谨慎。
更多的内容可以参考一些文章:
结语
至此,爬虫的一些涵盖的知识点也就差不多了,通过梳理发现计算机网络、编程基础、前端开发、后端开发、App 开发与逆向、网络安全、数据库、运维、机器学习都涵盖到了?上面总结的可以算是从爬虫小白到爬虫高手的路径了,里面每个方向其实可研究的点非常多,每个点做精了,都会非常了不起。
