资料
智能化解析是怎样的技术
我们知道,爬虫是帮助我们快速获取有效信息的。然而在做爬虫的过程中,我们会发现解析是件麻烦事。
比如一篇新闻吧,链接是:https://news.ifeng.com/c/7kQcQG2peWU,页面预览图如下:
我们需要从页面中提取出标题、发布人、发布时间、发布内容、图片等内容。一般情况下我们需要怎么办?答案是写规则。
那么规则都有什么呢?比如正则、CSS 选择器、XPath。我们需要对标题、发布时间、来源等内容做规则匹配,更有甚者需要正则表达式来辅助。我们可能需要用 re、BeautifulSoup、PyQuery 等库来实现内容的提取和解析。
但如果我们有成千上万个不同样式的页面该怎么办呢?它们来自成千上万个站点,难道我们还需要对它们一一写规则来匹配吗?这得要多大的工作量啊。另外这些万一处理不好还会出现解析问题。比如正则表达式在某些情况下匹配不了,CSS、XPath 选择器选错位也会出现问题。
想必你可能见过现在的浏览器有阅读模式,比如我们把这个页面用 Safari 浏览器打开,然后开启阅读模式,看看什么效果:

页面马上变得非常清爽,只保留了标题和需要读的内容。原先页面多余的导航栏、侧栏、评论等等都被去除了。它怎么做到的?难道是有人在里面写好规则了?那当然不可能的事。其实,这里面就用到了智能化解析了。
那么本课时,我们就来了解一下页面的智能化解析的相关知识。
智能化解析
所谓爬虫的智能化解析,顾名思义就是不再需要我们针对某一些页面来专门写提取规则了,我们可以利用一些算法来计算出页面特定元素的位置和提取路径。比如一个页面中的一篇文章,我们可以通过算法计算出来,它的标题应该是什么,正文应该是哪部分区域,发布时间等等。
其实智能化解析是非常难的一项任务,比如说你给人看一个网页的一篇文章,人可以迅速找到这篇文章的标题是什么,发布时间是什么,正文是哪一块,或者哪一块是广告位,哪一块是导航栏。但给机器来识别的话,它面临的是什么?仅仅是一系列的 HTML 代码而已。那究竟机器是怎么做到智能化提取的呢?其实这里面融合了多方面的信息。
- 比如标题。一般它的字号是比较大的,而且长度不长,位置一般都在页面上方,而且大部分情况下它应该和 title 标签里的内容是一致的。
- 比如正文。它的内容一般是最多的,而且会包含多个段落 p 或者图片 img 标签,另外它的宽度一般可能会占用到页面的三分之二区域,并且密度(字数除以标签数量)会比较大。
- 比如时间。不同语言的页面可能不同,但时间的格式是有限的,如 2019-02-20 或者 2019/02/20 等等,也有可能是美式的记法,顺序不同,这些也有特定的模式可以识别。
- 比如广告。它的标签一般可能会带有 ads 这样的字样,另外大多数可能会处于文章底部、页面侧栏,并可能包含一些特定的外链内容。
另外还有一些特点就不再一一赘述了,这其中包含了区块位置、区块大小、区块标签、区块内容、区块疏密度等等多种特征,另外很多情况下还需要借助于视觉的特征,所以说这里面其实结合了算法计算、视觉处理、自然语言处理等各个方面的内容。如果能把这些特征综合运用起来,再经过大量的数据训练,是可以得到一个非常不错的效果的。
业界进展
未来的话,页面也会越来越多,页面的渲染方式也会发生很大的变化,爬虫也会越来越难做,智能化爬虫也将会变得越来越重要。
目前工业界,其实已经有落地的算法应用了。经过我的一番调研,发现目前有这么几种算法或者服务对页面的智能化解析做得比较好:
- Diffbot,国外的一家专门做智能化解析服务的公司,https://www.diffbot.com。
- Boilerpipe,Java 语言编写的一个页面解析算法,https://github.com/kohlschutter/boilerpipe。
- Embedly,提供页面解析服务的公司,https://embed.ly/extract。
- Readability,是一个页面解析算法,但现在官方的服务已经关闭了,https://www.readability.com/。
- Mercury,Readability 的替代品,https://mercury.postlight.com/。
- Goose,Java 语音编写的页面解析算法,https://github.com/GravityLabs/goose。
那么这几种算法或者服务到底哪些好呢,Driffbot 官方曾做过一个对比评测,使用 Google 新闻的一些文章,使用不同的算法依次摘出其中的标题和文本,然后与真实标注的内容进行比较,比较的指标就是文字的准确率和召回率,以及根据二者计算出的 F1 分数。
其结果对比如下:
| Service/Software | Precision | Recall | F1-Score |
|---|---|---|---|
| Diffbot | 0.968 | 0.978 | 0.971 |
| Boilerpipe | 0.893 | 0.924 | 0.893 |
| Readability | 0.819 | 0.911 | 0.854 |
| AlchemyAPI | 0.876 | 0.892 | 0.850 |
| Embedly | 0.786 | 0.880 | 0.822 |
| Goose | 0.498 | 0.815 | 0.608 |
经过对比我们可以发现,Diffbot 的准确率和召回率都还比较高。这是一家专门做网页智能化提取的公司,Diffbot 自 2010 年以来就致力于提取 Web 页面数据,并提供许多 API 来自动解析各种页面。其中他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等多种算法,并且所有的页面都会考虑到当前页面的样式以及可视化布局,另外还会分析其中包含的图像内容、CSS 甚至 Ajax 请求。另外在计算一个区块的置信度时还考虑到了和其他区块的关联关系,基于周围的标记来计算每个区块的置信度。总之,Diffbot 也一直致力于这一方面的服务,整个 Diffbot 就是页面解析起家的,现在也一直专注于页面解析服务,准确率高也就不足为怪了。
但它们的算法并没有开源,只是以商业化 API 来售卖的,我也没有找到相关的论文介绍它们自己的具体算法。
不过,这里我们不妨拿它来做案例,稍微体会一下智能解析算法能达到一个怎样的效果。
接下来的内容,我们就以 Diffbot 为例来介绍下智能解析所能达到的效果。
Diffbot 页面解析
首先我们需要注册一个账号,它有 15 天的免费试用,注册之后会获得一个 Developer Token,这就是使用 Diffbot 接口服务的凭证。
接下来切换到它的测试页面中,链接为:https://www.diffbot.com/dev/home/,我们来测试一下它的解析效果到底是怎样的。
这里我们选择的测试页面就是上文所述的页面,链接为:https://news.ifeng.com/c/7kQcQG2peWU,API 类型选择 Article API,然后点击 Test Drive 按钮,接下来它就会出现当前页面的解析结果:
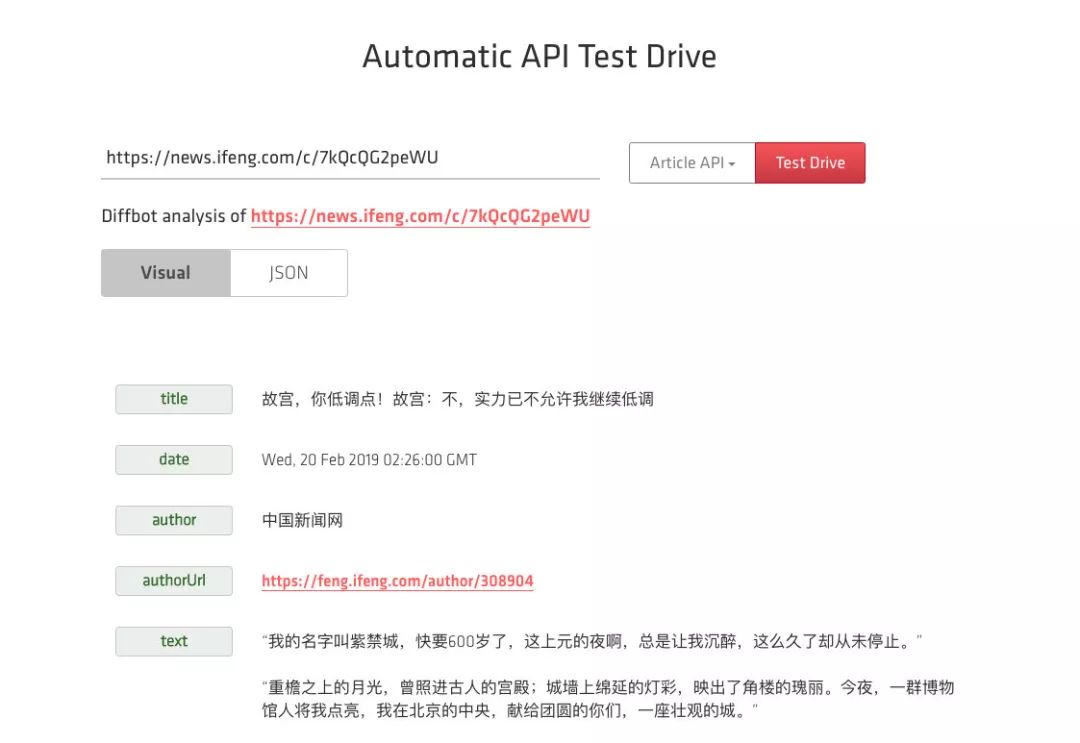
这时候我们可以看到,它帮我们提取出来了标题、发布时间、发布机构、发布机构链接、正文内容等等各种结果。而且目前来看都十分正确,时间也在自动识别后做了转码,是一个标准的时间格式。
接下来我们继续下滑,查看还有什么其他的字段,这里我们还可以看到有 html 字段,它和 text 不同的是 html 包含了文章内容的真实 HTML 代码,因此图片也会包含在里面,如图所示:

另外最后面还有 images 字段,它以列表形式返回了文章套图及每一张图的链接,另外还有文章的站点名称、页面所用语言等等结果,如图所示:
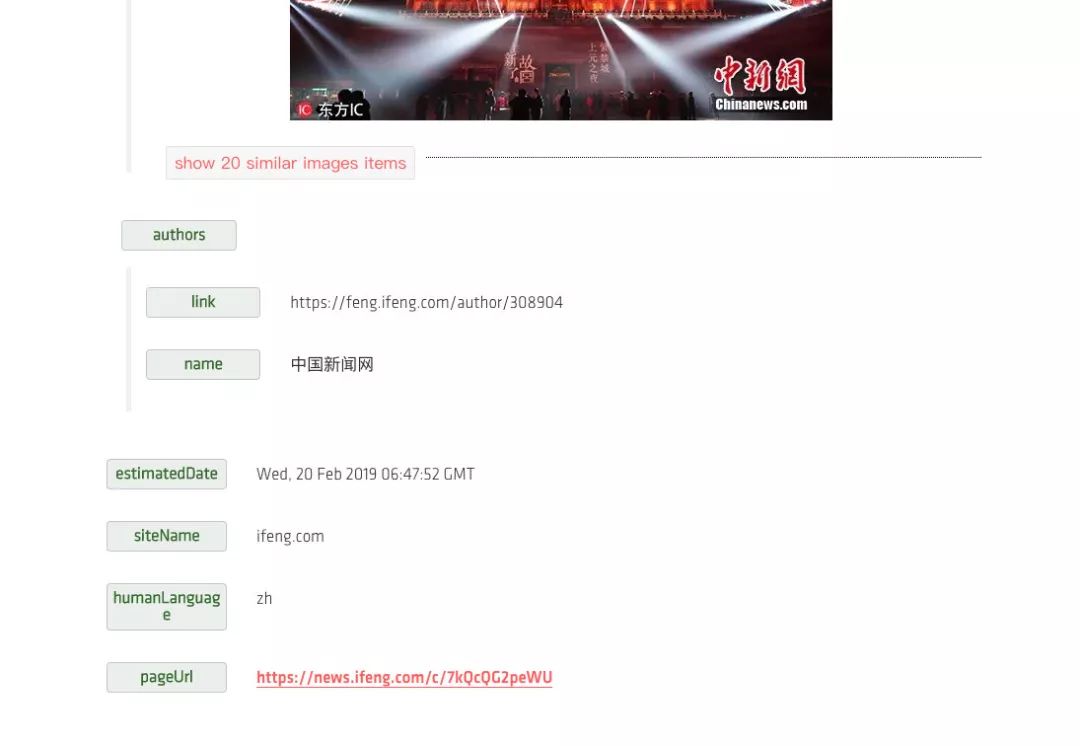
当然我们也可以选择 JSON 格式的返回结果,其内容会更加丰富,例如图片还返回了其宽度、高度、图片描述等等内容,另外还有各种其他的结果如面包屑导航等等结果,如图所示:
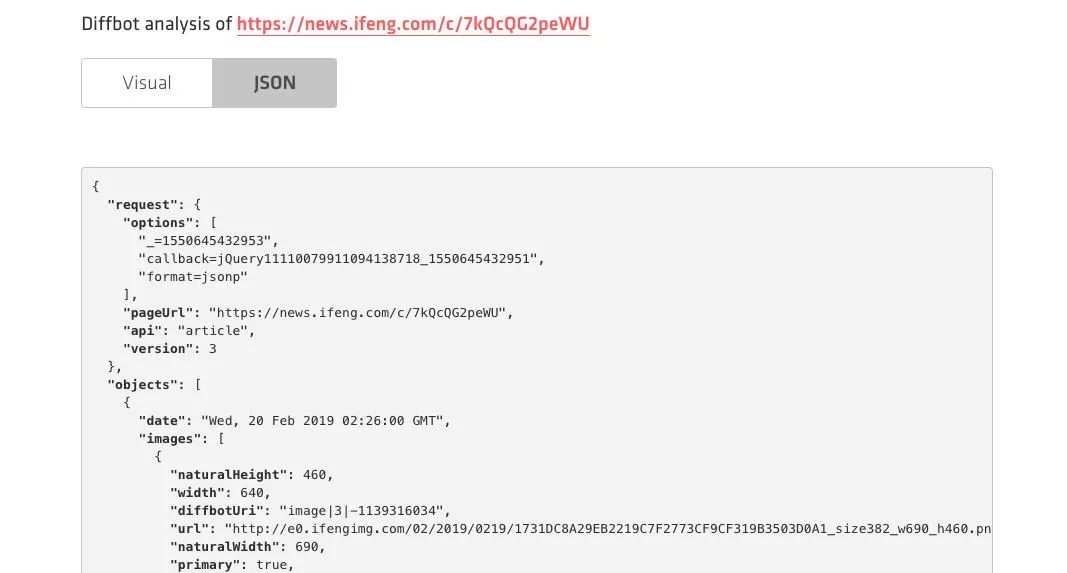
经过手工核对,发现其返回的结果都是完全正确的,准确率还是很高的。
所以说,如果你对准确率要求没有那么非常非常严苛的情况下,使用 Diffbot 的服务可以帮助我们快速地提取页面中所需的结果,省去了我们绝大多数的手工劳动,可以说是非常赞了。
但是,我们也不能总在网页上这么试吧。其实 Diffbot 也提供了官方的 API 文档,让我们来一探究竟。
Diffbot API
Driffbot 提供了多种 API,如 Analyze API、Article API、Disscussion API 等。
下面我们以 Article API 为例来说明一下它的用法,其官方文档地址为:https://www.diffbot.com/dev/docs/article/,API 调用地址为:
https://api.diffbot.com/v3/article
我们可以用 GET 方式来进行请求,其中的 Token 和 URL 都可以以参数形式传递给这个 API,其必备的参数有:
- token:即 Developer Token;
- url:即要解析的 URL 链接。
另外它还有几个可选参数。
- fields:用来指定返回哪些字段,默认已经有了一些固定字段,这个参数可以指定还可以额外返回可选字段。
- paging:针对多页文章,如果将这个参数设置为 false 则可以禁止多页内容拼接。
- maxTags:可以设置返回的 Tag 最大数量,默认是 10 个。
- tagConfidence:设置置信度的阈值,超过这个值的 Tag 才会被返回,默认是 0.5。
- discussion:如果将这个参数设置为 false,那么就不会解析评论内容。
- timeout:在解析的时候等待的最长时间,默认是 30 秒。
- callback:为 JSONP 类型的请求而设计的回调。
这里你可能关注的就是 fields 字段了,在这里我专门做了一下梳理,首先是一些固定字段。
- type:文本的类型,这里就是 article 了。
- title:文章的标题。
- text:文章的纯文本内容,如果是分段内容,那么其中会以换行符来分隔。
- html:提取结果的 HTML 内容。
- date:文章的发布时间,其格式为 RFC 1123。
- estimatedDate:如果日期时间不太明确,会返回一个预估的时间,如果文章超过两天或者没有发布日期,那么这个字段就不会返回。
- author:作者。
- authorUrl:作者的链接。
- discussion:评论内容,和 Disscussion API 返回结果一样。
- humanLanguage:语言类型,如英文还是中文等。
- numPages:如果文章是多页的,这个参数会控制最大的翻页拼接数目。
- nextPages:如果文章是多页的,这个参数可以指定文章后续链接。
- siteName:站点名称。
- publisherRegion:文章发布地区。
- publisherCountry:文章发布国家。
- pageUrl:文章链接。
- resolvedPageUrl:如果文章是从 pageUrl 重定向过来的,则返回此内容。
- tags:文章的标签或者文章包含的实体,根据自然语言处理技术和 DBpedia 计算生成,是一个列表,里面又包含了子字段:
- label:标签名。
- count:标签出现的次数。
- score:标签置信度。
- rdfTypes:如果实体可以由多个资源表示,那么则返回相关的 URL。
- type:类型。
- uri:Diffbot Knowledge Graph 中的实体链接。
- images:文章中包含的图片。
- videos:文章中包含的视频。
- breadcrumb:面包屑导航信息。
- diffbotUri:Diffbot 内部的 URL 链接。
以上的预定字段就是如果可以返回那就会返回的字段,是不能定制化配置的,另外我们还可以通过 fields 参数来指定扩展如下可选字段。
- quotes:引用信息。
- sentiment:文章的情感值,-1 ~ 1 之间。
- links:所有超链接的顶级链接。
- querystring:请求的参数列表。
好,以上便是这个 API 的用法,你可以申请之后使用这个 API 来做智能化解析了。
下面我们用一个实例来看一下这个 API 的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24496d5113d528306528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里首先定义了 API 的链接,然后指定了 params 参数,即 GET 请求参数。
参数中包含了必选的 token、url 字段,也设置了可选的 fields 字段,其中 fields 为可选的扩展字段 meta 标签。
我们来看下运行结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019/0219/1731DC8A29EB2219C7F2773CF9CF319B3503D0A1_size382_w690_h460.png",
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/2019/0219/1731DC8A29EB2219C7F2773CF9CF319B3503D0A1_size382_w690_h460.png",
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。...</blockquote> </blockquote>",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可见其返回了如上的内容,是一个完整的 JSON 格式,其中包含了标题、正文、发布时间等等各种内容。
可见,不需要我们配置任何提取规则,我们就可以完成页面的分析和抓取,得来全不费功夫。
另外 Diffbot 还提供了几乎所有语言的 SDK 支持,我们也可以使用 SDK 来实现如上功能,链接为:https://www.diffbot.com/dev/docs/libraries/,如果你使用 Python 的话,可以直接使用 Python 的 SDK 即可,Python 的 SDK 链接为:https://github.com/diffbot/diffbot-python-client。
这个库并没有发布到 PyPi,需要自己下载并导入使用,另外这个库是使用 Python 2 写的,其实本质上就是调用了 requests 库,如果你感兴趣的话可以看一下。
下面是一个调用示例:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/javascript-patterns/'
api = 'article'
response = diffbot.request(url, token, api)
通过这行代码我们就可以通过调用 Article API 来分析我们想要的 URL 链接了,返回结果是类似的。
具体的用法你直接看下它的源码注释就一目了然了,还是很清楚的。
总结
好,以上便是对智能化提取页面原理的基本介绍以及对 Diffbot 的用法的讲解,后面我会继续介绍其他的智能化解析方法以及一些相关实战。
智能化解析工具使用
上一课时我们介绍了智能化解析技术的一些基本原理和效果,并且通过 Diffbot 体验了一下智能化解析能达到的效果。
但 Diffbot 是商业化应用,而且是收费的,本课时将再介绍几个开源的智能解析库,稍微分析一下它们的源码逻辑。虽然准确率并不是很高,但我们通过这些内容深入研究它的一些源码和实现,就可以对智能解析有更深入地认识。
智能文本提取
目前来说,智能文本提取可以分为三类:
-
基于网页文档内容的提取方法
-
基于 DOM 结构信息的提取方法
-
基于视觉信息的提取方法
基于网页文档的提取方法将 HTML 文档视为文本进行处理,适用于处理含有大量文本信息且结构简单易于处理的单记录网页,或者具有实时要求的在线分析网页应用。 这种方式主要利用自然语言处理的相关技术实现,通过理解文本语义、分析上下文、设定提取规则等,实现对大段网页文档的快速处理。其中,较为知名的方法有 TSIMMIS、Web-OQL、Serrano、FAR-SW 和 FOREST,但这些方法通常需要人工的参与,且存在耗时长、效率低的弊端。
基于 DOM 结构信息的方法将 HTML 文档解析为相应的 DOM 树,然后根据 DOM 树的语法结构创建提取规则, 相对于以前的方法而言有了更高的性能和准确率。 W4F 和 XWRAP 将 HTML 文档解析成 DOM 树,然后通过组件化引导用户通过人工选择或者标记生成目标包装器代码。Omini、IEPAD 和 ITE 提取 DOM 树上的关键路径,获取其中存在的重复模式。MDR 和 DEPTA 挖掘了页面中的数据区域,得到数据记录的模式。CECWS 通过聚类算法从数据库中提取出自同一网站的一组页面,并进行 DOM 树结构的对比,删除其中的静态部分,保留动态内容作为信息提取的结果。
虽然此类方法相对于上一类方法具有较高的提取精度,且克服了对大段连续文本的依赖,但由于网页的 DOM 树通常较深,且含有大量 DOM 节点,因此基于 DOM 结构信息的方法具有较高的时间和空间消耗。目前来说,大部分原理还是基于 DOM 节点的文本密度、标点符号密度等计算的,其准确率还是比较可观的。今天所介绍的 Readability 和 Newspaper 的库,其实现原理是类似的。
目前比较先进的是基于视觉信息的网页信息提取方法,通过浏览器接口或者内核对目标网页预渲染,然后基于网页的视觉规律提取网页数据记录。经典的 VIPS 算法首先从 DOM 树中提取出所有合适的页面区域,然后根据这些页面和分割条重新构建 Web 页面的语义结构。作为对 VIPS 的拓展,ViNT、ViPER、ViDE 也成功利用了网页的视觉特征来实现数据提取。CMDR 为通过神经网络学习多记录型页面中的特征,结合基于 DOM 结构信息的 MDR 方法,挖掘社区论坛页面的数据区域。
与上述方法不同,VIBS 将图像领域的 CNN 卷积神经网络运用于网页的截图,同时通过类 VIPS 算法生成视觉块,最后结合两个阶段的结果识别网页的正文区域。另外还有最新的国内提出的 VBIE 方法,基于网页视觉的基础上改进,可以实现无监督的网页信息提取。
以上内容主要参考自论文:《王卫红等:基于可视块的多记录型复杂网页信息提取算法》,算法可从该论文参考文献查阅。
下面我们来介绍两个比较基础的工具包 Readability 和 Newspaper 的用法,这两个包经我测试其实准确率并不是很好,主要是让你大致对智能解析有初步的理解。后面还会介绍一些更加强大的智能化解析算法。
Readability
Readability 实际上是一个算法,并不是一个针对某个语言的库,其主要原理是计算了 DOM 的文本密度。另外根据一些常见的 DOM 属性如 id、class 等计算了一些 DOM 的权重,最后分析得到了对应的 DOM 区块,进而提取出具体的文本内容。
现在搜索 Readability 其实已经找不到了,取而代之的是一个 JavaScript 工具包,即 mercury-parser,据我所知 Readability 应该不维护了,换成了 mercury-parser。后者现在也做成了一个 Chrome 插件,大家可以下载使用一下。
回归正题,这次主要介绍的是 Python 的 Readability 实现,现在其实有很多开源版本,本课时选取的是 https://github.com/buriy/python-readability,是基于最早的 Python 版本的 Readability 库二次开发的,现在已经发布到了 PyPi,可以直接下载安装使用。
安装很简单,通过 pip 安装即可:
pip3 install readability-lxml
安装好了之后便可以通过导入 readability 使用了。我们随意从网上找一个新闻页面,其页面截图如下图所示:
我们的目的就是它的正文、标题等内容。下面用 Readability 试一下,示例如下:
import requests
from readability import Document
url = 'https://tech.163.com/19/0909/08/EOKA3CFB00097U7S.html'
html = requests.get(url).content
doc = Document(html)
print('title:', doc.title())
print('content:', doc.summary(html_partial=True))
在这里直接用 requests 库对网页进行了请求,获取了其 HTML 页面内容,赋值为 html。
然后引入了 readability 里的 Document 类,使用 html 变量对其进行初始化,接着分别调用了 title 方法和 summary 方法获得了其标题和正文内容。
这里 title 方法就是获取文章标题的,summary 是获取文章正文的,但是它获取的正文可能包含了一些 HTML 标签。这个 summary 方法可以接收一个 html_partial 参数,如果设置为 true,返回的结果则不会再带有 <html><body> 标签。
看下运行结果:
title: 今年iPhone只有小改进?分析师:还有其他亮点_网易科技
content: <div><div class="post_text" id="endText">
<p class="otitle">
(原标题:Apple Bets More Cameras Can Keep iPhone Humming)
</p>
<p class="f_center"><img alt="今年iPhone只有小改进?分析师:还有其他亮点" src="http://cms-bucket.ws.126.net/2019/09/09/d65ba32672934045a5bfadd27f704bc1.jpeg"/><span>图示:苹果首席执行官蒂姆·库克(Tim Cook)在6月份举行的苹果全球开发者大会上。</span></p><p>网易科技讯 9月9日消息,据国外媒体报道,和过去的12个年头一样,新款
... 中间省略 ...
<p>苹果还即将推出包括电视节目和视频游戏等内容的新订阅服务。分析师表示,该公司最早可能在本周宣布TV+和Arcade等服务的价格和上线时间。</p><p>Strategy Analytics的尼尔·莫斯顿(Neil Mawston)表示,可穿戴设备和服务的结合将是苹果业务超越iPhone的关键。他说,上一家手机巨头诺基亚公司在试图进行类似业务转型时就陷入了困境之中。(辰辰)</p><p><b>相关报道:</b></p><p><a href="https://tech.163.com/19/0908/09/EOHS53RK000999LD.html" target="_self" urlmacroreplace="false">iPhone 11背部苹果Logo改为居中:为反向无线充电</a></p><p><a href="https://tech.163.com/19/0907/08/EOF60CBC00097U7S.html" target="_self" urlmacroreplace="false">2019年新iPhone传言汇总,你觉得哪些能成真</a> </p><p/>
<p/>
<div class="ep-source cDGray">
<span class="left"><a href="http://tech.163.com/"><img src="https://static.ws.126.net/cnews/css13/img/end_tech.png" alt="王凤枝" class="icon"/></a> 本文来源:网易科技报道 </span>
<span class="ep-editor">责任编辑:王凤枝_NT2541</span>
</div>
</div>
</div>
可以看到,标题提取是正确的,正文其实也是正确的,不过这里还包含了一些 HTML 标签,比如 <img>、<p> 等,我们可以进一步通过一些解析库来解析。
看下源码,比如提取标题的方法:
def normalize_entities(cur_title):
entities = {
u'\u2014':'-',
u'\u2013':'-',
u'—': '-',
u'–': '-',
u'\u00A0': ' ',
u'\u00AB': '"',
u'\u00BB': '"',
u'"': '"',
}
for c, r in entities.items():
if c in cur_title:
cur_title = cur_title.replace(c, r)
return cur_title
def norm_title(title):
return normalize_entities(normalize_spaces(title))
def get_title(doc):
title = doc.find('.//title')
if title is None or title.text is None or len(title.text) == 0:
return '[no-title]'
return norm_title(title.text)
def title(self):
"""Returns document title"""
return get_title(self._html(True))
title 方法实际上就是调用了一个 get_title 方法,它是怎么做的呢?实际上就是用了一个 XPath 只解析了 <title> 标签里面的内容,别的没了。如果没有,那就返回 [no-title]。
def summary(self, html_partial=False):
ruthless = True
while True:
self._html(True)
for i in self.tags(self.html, 'script', 'style'):
i.drop_tree()
for i in self.tags(self.html, 'body'):
i.set('id', 'readabilityBody')
if ruthless:
self.remove_unlikely_candidates()
self.transform_misused_divs_into_paragraphs()
candidates = self.score_paragraphs()
best_candidate = self.select_best_candidate(candidates)
if best_candidate:
article = self.get_article(candidates, best_candidate,
html_partial=html_partial)
else:
if ruthless:
ruthless = False
continue
else:
article = self.html.find('body')
if article is None:
article = self.html
cleaned_article = self.sanitize(article, candidates)
article_length = len(cleaned_article or '')
retry_length = self.retry_length
of_acceptable_length = article_length >= retry_length
if ruthless and not of_acceptable_length:
ruthless = False
continue
else:
return cleaned_article
这里我删除了一些冗余的调试代码,只保留了核心代码,其核心实现就是先去除一些干扰内容,然后找出一些疑似正文的 candidates,接着再去寻找最佳匹配的 candidates,最后提取其内容返回即可。
然后再找到获取 candidates 方法里面的 score_paragraphs 方法,又追踪到一个 score_node 方法,就是为每一个节点打分的,其实现如下:
def score_node(self, elem):
content_score = self.class_weight(elem)
name = elem.tag.lower()
if name in ["div", "article"]:
content_score += 5
elif name in ["pre", "td", "blockquote"]:
content_score += 3
elif name in ["address", "ol", "ul", "dl", "dd", "dt", "li", "form", "aside"]:
content_score -= 3
elif name in ["h1", "h2", "h3", "h4", "h5", "h6", "th", "header", "footer", "nav"]:
content_score -= 5
return {
'content_score': content_score,
'elem': elem
}
这是什么意思呢?你看如果这个节点标签是 div 或者 article 等可能表征正文区块的话,就加 5 分;如果是 aside 等表示侧栏内容的话,就减 3 分。这些打分也没有什么非常标准的依据,可能是根据经验累积的规则。
另外还有一些方法里面引用了一些正则匹配来进行打分或者替换,其定义如下:
REGEXES = {
'unlikelyCandidatesRe': re.compile('combx|comment|community|disqus|extra|foot|header|menu|remark|rss|shoutbox|sidebar|sponsor|ad-break|agegate|pagination|pager|popup|tweet|twitter', re.I),
'okMaybeItsACandidateRe': re.compile('and|article|body|column|main|shadow', re.I),
'positiveRe': re.compile('article|body|content|entry|hentry|main|page|pagination|post|text|blog|story', re.I),
'negativeRe': re.compile('combx|comment|com-|contact|foot|footer|footnote|masthead|media|meta|outbrain|promo|related|scroll|shoutbox|sidebar|sponsor|shopping|tags|tool|widget', re.I),
'divToPElementsRe': re.compile('<(a|blockquote|dl|div|img|ol|p|pre|table|ul)', re.I),
#'replaceBrsRe': re.compile('(<br[^>]*>[ \n\r\t]*){2,}',re.I),
#'replaceFontsRe': re.compile('<(\/?)font[^>]*>',re.I),
#'trimRe': re.compile('^\s+|\s+$/'),
#'normalizeRe': re.compile('\s{2,}/'),
#'killBreaksRe': re.compile('(<br\s*\/?>(\s| ?)*){1,}/'),
'videoRe': re.compile('https?:\/\/(www\.)?(youtube|vimeo)\.com', re.I),
#skipFootnoteLink: /^\s*(\[?[a-z0-9]{1,2}\]?|^|edit|citation needed)\s*$/i,
}
比如这里定义了 unlikelyCandidatesRe,就是不像 candidates 的 pattern,比如 foot、comment 等,碰到这样的标签或 pattern 的话,在计算分数的时候都会减分,另外还有其他的 positiveRe、negativeRe 也是一样的原理,分别对匹配到的内容进行加分或者减分。
这就是 Readability 的原理,即基于一些规则匹配的打分模型,很多规则其实来源于经验的累积,分数的计算规则应该也是不断地调优得出来的。
其他的就没了,Readability 并没有提供提取时间、作者的方法,另外此种方法的准确率也是有限的,但多少还是省去了一些人工成本。
Newspaper
另外还有一个智能解析的库,叫作 Newspaper,提供的功能更强一些,但是准确率上个人感觉和 Readability 差不太多。
这个库分为 Python2 和 Python3 两个版本,Python2 下的版本叫作 newspaper,Python3 下的版本叫作 newspaper3k。这里我们使用 Python3 版本来进行测试。
点击这里获取 GitHub 地址,点击这里获取官方文档地址。
在安装之前需要安装一些依赖库,点击这里可参考官方的说明。
安装好必要的依赖库之后,就可以使用 pip 安装了:
pip3 install newspaper3k
安装成功之后便可以导入使用了。
下面我们先用官方提供的实例来过一遍它的用法,其页面截图如下:
下面用一个实例来感受一下:
from newspaper import Article
url = 'https://fox13now.com/2013/12/30/new-year-new-laws-obamacare-pot-guns-and-drones/'
article = Article(url)
article.download()
# print('html:', article.html)
article.parse()
print('authors:', article.authors)
print('date:', article.publish_date)
print('text:', article.text)
print('top image:', article.top_image)
print('movies:', article.movies)
article.nlp()
print('keywords:', article.keywords)
print('summary:', article.summary)
这里从 newspaper 库里面先导入了 Article 类,然后直接传入 url 即可。首先需要调用它的 download 方法,将网页爬取下来,否则直接进行解析会抛出错误。
但我总感觉这个设计挺不友好的,parse 方法不能判断下,如果没执行 download 就自动执行 download 方法吗?如果不 download 其他的不什么都干不了吗?
好的,然后我们再执行 parse 方法进行网页的智能解析,这个功能就比较全了,能解析 authors、publish_date、text 等,除了正文还能解析作者、发布时间等。
另外这个库还提供了一些 NLP 的方法,比如获取关键词、获取文本摘要等,在使用前需要先执行以下 nlp 方法。
最后运行结果如下:
authors: ['Cnn Wire']
date: 2013-12-30 00:00:00
text: By Leigh Ann Caldwell
WASHINGTON (CNN) — Not everyone subscribes to a New Year’s resolution, but Americans will be required to follow new laws in 2014.
Some 40,000 measures taking effect range from sweeping, national mandates under Obamacare to marijuana legalization in Colorado, drone prohibition in Illinois and transgender protections in California.
Although many new laws are controversial, they made it through legislatures, public referendum or city councils and represent the shifting composition of American beliefs.
...
...
Colorado: Marijuana becomes legal in the state for buyers over 21 at a licensed retail dispensary.
(Sourcing: much of this list was obtained from the National Conference of State Legislatures).
top image: https://localtvkstu.files.wordpress.com/2012/04/national-news-e1486938949489.jpg?quality=85&strip=all
movies: []
keywords: ['drones', 'national', 'guns', 'wage', 'law', 'pot', 'leave', 'family', 'states', 'state', 'latest', 'obamacare', 'minimum', 'laws']
summary: Oregon: Family leave in Oregon has been expanded to allow eligible employees two weeks of paid leave to handle the death of a family member.
Arkansas: The state becomes the latest state requiring voters show a picture ID at the voting booth.
Minimum wage and former felon employmentWorkers in 13 states and four cities will see increases to the minimum wage.
New Jersey residents voted to raise the state’s minimum wage by $1 to $8.25 per hour.
California is also raising its minimum wage to $9 per hour, but workers must wait until July to see the addition.
这里省略了一些输出结果。
可以看到作者、日期、正文、关键词、标签、缩略图等信息都被打印出来了,还算是不错的。
但这个毕竟是官方的实例,肯定是好的。我们再测试一下刚才的例子,看看效果如何(点击这里网址链接),改写代码如下:
from newspaper import Article
url = 'https://tech.163.com/19/0909/08/EOKA3CFB00097U7S.html'
article = Article(url, language='zh')
article.download()
# print('html:', article.html)
article.parse()
print('authors:', article.authors)
print('title:', article.title)
print('date:', article.publish_date)
print('text:', article.text)
print('top image:', article.top_image)
print('movies:', article.movies)
article.nlp()
print('keywords:', article.keywords)
print('summary:', article.summary)
这里我们将链接换成了新闻的链接,另外在 Article 初始化的时候还加了一个参数 language,其值为 zh,代表中文。
然后我们看下运行结果:
Building prefix dict from /usr/local/lib/python3.7/site-packages/jieba/dict.txt ...
Dumping model to file cache /var/folders/1g/l2xlw12x6rncs2p9kh5swpmw0000gn/T/jieba.cache
Loading model cost 1.7178938388824463 seconds.
Prefix dict has been built succesfully.
authors: []
title: 今年iPhone只有小改进?分析师:还有其他亮点
date: 2019-09-09 08:10:26+08:00
text: (原标题:Apple Bets More Cameras Can Keep iPhone Humming)
图示:苹果首席执行官蒂姆·库克(Tim Cook)在6月份举行的苹果全球开发者大会上。
网易科技讯 9月9日消息,据国外媒体报道,和过去的12个年头一样,新款iPhone将成为苹果公司本周所举行年度宣传活动的主角。但人们的注意力正转向需要推动增长的其他苹果产品和服务。
...
...
Strategy Analytics的尼尔·莫斯顿(Neil Mawston)表示,可穿戴设备和服务的结合将是苹果业务超越iPhone的关键。他说,上一家手机巨头诺基亚公司在试图进行类似业务转型时就陷入了困境之中。(辰辰)
相关报道:
iPhone 11背部苹果Logo改为居中:为反向无线充电
2019年新iPhone传言汇总,你觉得哪些能成真
top image: https://www.163.com/favicon.ico
movies: []
keywords: ['trust高级投资组合经理丹摩根dan', 'iphone', 'mawston表示可穿戴设备和服务的结合将是苹果业务超越iphone的关键他说上一家手机巨头诺基亚公司在试图进行类似业务转型时就陷入了困境之中辰辰相关报道iphone', 'xs的销售疲软状况迫使苹果在1月份下调了业绩预期这是逾15年来的第一次据贸易公司susquehanna', 'xs机型发布后那种令人失望的业绩重演iphone', '今年iphone只有小改进分析师还有其他亮点', 'more', 'xr和iphone', 'morgan说他们现在没有任何真正深入的进展只是想继续让iphone这款业务继续转下去他乐观地认为今年发布的新款手机将有足够多的新功能为一个非常成熟的产品增加额外的功能让火车继续前进这种仅限于此的态度说明了苹果自2007年发布首款iphone以来所面临的挑战iphone销售占苹果公司总营收的一半以上这让苹果陷入了一个尴尬的境地既要维持核心产品的销量另一方面又需要减少对它的依赖瑞银ubs今年5月份对8000名智能手机用户进行了相关调查其发布的年度全球调查报告显示最近iphone在人脸识别技术等方面的进步并没有引起一些消费者的共鸣他们基本上都认为苹果产品没有过去几年那么独特或者惊艳品牌也没有过去几年那么有吸引力很多人使用老款手机的时间更长自己认为也没有必要升级到平均售价949美元的新款iphone苹果需要在明年销售足够多的iphone以避免像去年9月份iphone', 'keep', '原标题apple']
summary: (原标题:Apple Bets More Cameras Can Keep iPhone Humming)图示:苹果首席执行官蒂姆·库克(Tim Cook)在6月份举行的苹果全球开发者大会上。网易科技讯 9月9日消息,据国外媒体报道,和过去的12个年头一样,新款iPhone将成为苹果公司本周所举行...亚公司在试图进行类似业务转型时就陷入了困境之中。(辰辰)相关报道:iPhone 11背部苹果Logo改为居中:为反向无线充电2019年新iPhone传言汇总,你觉得哪些能成真
由于中间正文很长,这里省略了一部分,可以看到运行时首先加载了一些中文的库包,比如 jieba 所依赖的词表等。
解析结果中,日期的确是解析对了,因为这个日期格式的确比较规整,但这里还自动给我们加了东八区的时区,贴心了。作者没有提取出来,可能是没匹配到 来源 两个字吧,或者词库里面没有,标题、正文的提取还算比较正确,也或许这个案例的确比较简单。
另外对于 NLP 部分,获取的关键词长度有点太长了,summary 也有点冗余。
另外 Newspaper 还提供了一个较为强大的功能,就是 build 构建信息源。官方的介绍其功能就是构建一个新闻源,可以根据传入的 URL 来提取相关文章、分类、RSS 订阅信息等。
我们用实例感受一下:
import newspaper
source = newspaper.build('http://www.sina.com.cn/', language='zh')
for category in source.category_urls():
print(category)
for article in source.articles:
print(article.url)
print(article.title)
for feed_url in source.feed_urls():
print(feed_url)
在这里我们传入了新浪的官网,调用了 build 方法,构建了一个 source,然后输出了相关的分类、文章、RSS 订阅等内容,运行结果如下:
http://cul.news.sina.com.cn
http://www.sina.com.cn/
http://sc.sina.com.cn
http://jiangsu.sina.com.cn
http://gif.sina.com.cn
....
http://tj.sina.com.cn
http://travel.sina.com.cn
http://jiaoyi.sina.com.cn
http://cul.sina.com.cn
https://finance.sina.com.cn/roll/2019-06-12/doc-ihvhiqay5022316.shtml
经参头版:激发微观主体活力加速国企改革
http://eladies.sina.com.cn/feel/xinli/2018-01-25/0722/doc-ifyqwiqk0463751.shtml
我们别再联系了
http://finance.sina.com.cn/roll/2018-05-13/doc-ihamfahx2958233.shtml
新违约时代到来!违约“常态化”下的市场出清与换血
http://sports.sina.com.cn/basketball/2019worldcup/2019-09-08/doc-iicezzrq4390554.shtml
罗健儿26分韩国收首胜
...
http://travel.sina.com.cn/outbound/pages/2019-09-05/detail-iicezzrq3622449.shtml
菲律宾海滨大道 夜晚让人迷离
http://travel.sina.com.cn/outbound/pages/2016-08-19/detail-ifxvcnrv0334779.shtml
关岛 用双脚尽情享受阳光与海滩
http://travel.sina.com.cn/domestic/pages/2019-09-04/detail-iicezzrq3325092.shtml
秋行查干浩特草原
http://travel.sina.com.cn/outbound/pages/2019-09-03/detail-iicezueu3050710.shtml
白羊座的土豪之城迪拜
http://travel.sina.com.cn/video/baidang/2019-08-29/detail-ihytcitn2747327.shtml
肯辛顿宫藏着维多利亚的秘密
http://cd.auto.sina.com.cn/bdcs/2017-08-15/detail-ifyixias1051586.shtml
可以看到它输出了非常多的类别链接,另外还有很多文章列表,由于没有 RSS 订阅内容,这里没有显示。
下面把站点换成我的博客,博客截图如下:
看看运行结果:
https://cuiqingcai.com
https://cuiqingcai.com
似乎一篇文章都没有,RSS 也没有,可见其功能还有待优化。
Newspaper 的基本用法先介绍到这里,更加详细的用法可以参考官方文档:https://newspaper.readthedocs.io。个人感觉其中的智能解析可以用用,不过据我的个人经验,感觉还是很多解析不对或者解析不全的。
以上便是 Readability 和 Newspaper 的介绍。
其他方案
另外除了这两个库其实还有一些比较优秀的算法,由于我们处理的大多数为中文文档,所以一些在中文上面的研究还是比较有效的,在这里列几个值得借鉴的中文论文供大家参考:
-
洪鸿辉等,基于文本及符号密度的网页正文提取方法
-
梁东等,基于支持向量机的网页正文内容提取方法
-
王卫红等,基于可视块的多记录型复杂网页信息提取算法
后面我们还会再根据一些论文的基本原理并结合一些优秀的开源实现来深入讲解智能解析算法。
页面智能解析算法原理解析
在前面的课时中我们了解了智能化解析技术的一些提取效果和相关开源工具,接下来我们就来深入剖析一下智能解析算法的原理。
目标
我们还是以新闻网站为例,比如这个链接:https://news.ifeng.com/c/7kQcQG2peWU,页面预览如图所示:
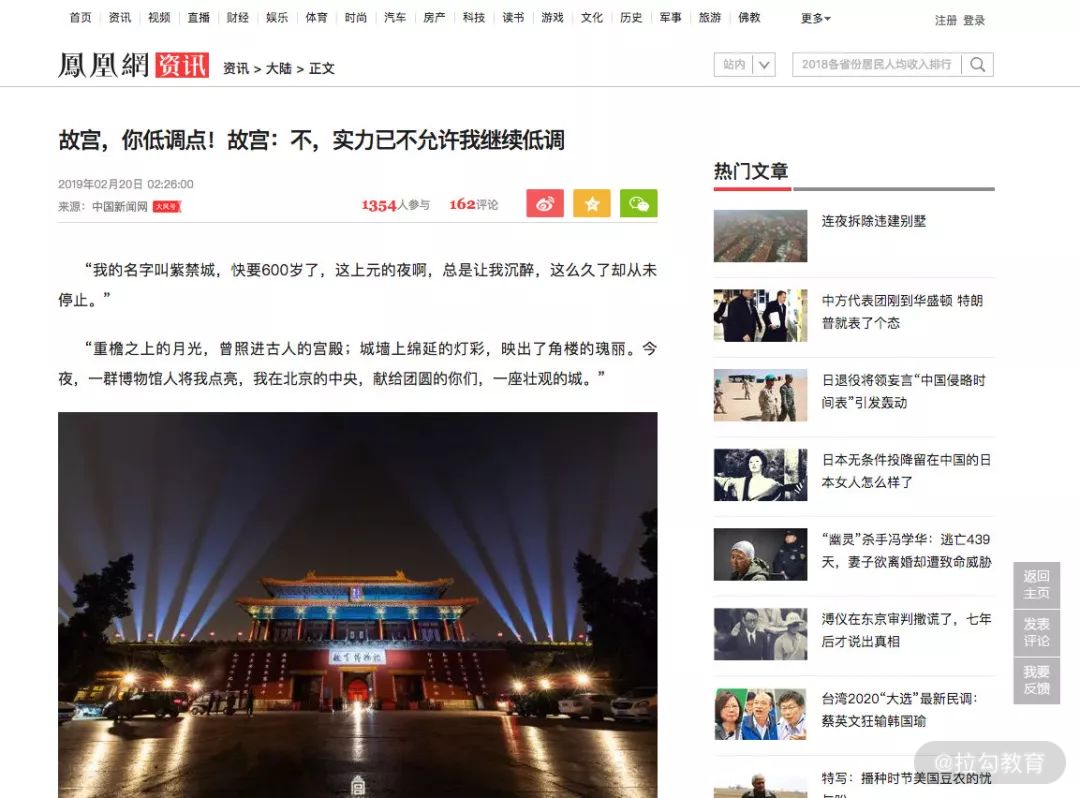
在第一节我们讲解了利用 Diffbot 提取其中的标题、发布人、发布时间、正文、图片等信息,准确率还是不错的,但这毕竟是一个收费服务,我们并不能了解到其实现原理。
接下来我们就来深入剖析一下这些字段的解析方法,虽然本节介绍的不一定是准确率最高、最前沿的方法,但是经过一些验证,其效果还是相对不错的。
本节我们会针对新闻详情页,介绍如下几个字段的智能解析方法:
-
标题
-
正文
-
发布时间
-
作者
这四个字段是新闻详情页里面最重要的信息,所以这里主要就介绍这四个字段的提取方法。
标题
一般来说,标题是相对比较好提取的,因为一般新闻会把标题放在 title 这个标签之下,比如 https://news.ifeng.com/c/7kQcQG2peWU 这个链接,我们可以看一下网页 title 部分的源码,内容如下:
<title>故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰网资讯_凤凰网</title>
这里如果我们直接提取的话,得到的内容如下:
故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰网资讯_凤凰网
但实际上,title 的内容应该为:
故宫,你低调点!故宫:不,实力已不允许我继续低调
所以,如果我们一味地提取 title 标签内的内容是不准确的,因为网站本身会额外增加一些信息,比如拼接上站点本身的信息等等。
那这个时候怎么办呢?在绝大部分情况下,标题是通过 h 节点来表示的,一般为 h1、h2、h3、h4 等,其内部的文本一般就代表完整的标题,那问题又来了,HTML 里面那么多 h 节点,我们又怎么确定标题对应的是哪个 h 节点呢?
答案你应该也想到了,我们用 title 的内容和 h 节点的内容结合起来不就好判断了吗?
这里我们就能总结出两个提取思路:
-
提取页面的 h 节点,如 h1、h2 等节点内容,然后将内容和 title 的文本进行比对,找出和 title 最相似的内容。比对的方法可以使用编辑距离或最长公共子串。
-
如果未找到 h 节点,则只能使用 title 节点。
一般来说,使用以上方法几乎可以应对 90% 以上标题的提取。
另外如果某些网站为了 SEO 效果比较好,通常会添加一些 meta 标签,如 url、title、keywords、category 等信息,这些信息也可以成为一些参考依据,进一步校验或补充网站的基本信息。
比如在上面的例子中,我们可以看到有一个 meta 节点,其内容如下:
<meta property="og:title" content="故宫,你低调点!故宫:不,实力已不允许我继续低调">
这里我们可以看到这个 meta 节点指定了 property 为 og:title,这是一种常见写法,其内容正好就是标题的信息,通过这部分信息我们也能进行标题的提取。
因此,综上所述,结合 meta、title、h 节点,我们就可以应对绝大多数标题的提取了。
正文
正文可以说是新闻页面最难提取且最为重要的部分了,如果我们不能有效地把正文内容提取出来,那么这次解析就算是失败了一大半了。
在之前介绍过的 Readability 算法中,我们大致上可以得知其中有一个打分算法,比如我们可以将 HTML 代码进行解析,形成 DOM 树,然后对其中的每个节点进行打分,比如给非正文的节点 style、script、sidebar、footer 等打负分,对一些 p、article 节点打正分,最后得到一系列节点打分结果,但如果仅仅靠这种算法,其准确率还是比较低的。
但在这个过程中,我们可以得到一些启发,比如:
-
正文内容一般会被包含在 body 节点的 p 节点中,而且 p 节点一般不会独立存在,一般都会存在于 div 等节点内。
-
正文内容对应的 p 节点也不一定全都是正文内容,可能掺杂其他的噪声,如网站的版权信息、发布人、文末广告等,这部分属于噪声。
-
正文内容对应的 p 节点中会夹杂一些 style、script 等节点,并非正文内容。
-
正文内容对应的 p 节点内可能包含 code、span 等节点,这些大部分属于正文中的特殊样式字符,多数情况下也需要归类到正文中。
受开源项目 https://github.com/kingname/GeneralNewsExtractor 和论文《洪鸿辉,等 基于文本符号密度的网页正文提取方法》的启发,我们得知了一个有效的正文文本提取依据指标,那就是文本密度。
那么文本密度是什么呢?其实就类似单位节点所包含的文字个数。我们借用上述论文的内容,定义一个节点的文本密度:
如果 i 为 HTML DOM 树中的一个节点,那么该节点的文本密度定义为:

这里四个指标你需要好好理解下,其实就基本上等同于单位标签内所包含的文字个数,但这里额外考虑了超链接的情况。因为一般来说,正文中所带的超链接是比较少的,而对于一些侧边栏、底栏一些区域,带有超链接的比率是非常高的,文本密度就会低下来,因此就容易排除了。
另外论文还提到了一个指标,叫作符号密度。论文研究发现,正文中一般都带有标点符号,而网页链接、广告信息由于文字比较少,通常是不包含标点符号的,所以我们可以通过符号密度来排除一些内容。
符号密度的定义如下:

这里符号密度为文字数量和符号数量的比值。
在论文中,通过二者结合来提取,正文提取的准确率几乎可以达到 99%,论文作者对以上算法进行了评测,计算了在不同网站上 Precision、Recall、F1 值,结果如下:
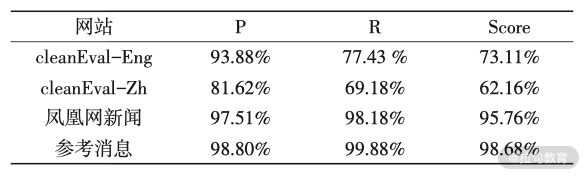
可以看到该算法在凤凰网新闻上的表现整体可以达到 95% 以上。
另外除了基于密度的算法,我们还可以结合视觉来对正文进行识别。一般来说,正文所占的版面是最大的,所以我们可以通过计算节点所占区域的大小来排除一些干扰,比如如果我们查找到两块内容都疑似正文区域,而这两块区域的网页面积却一个很大,一个很小,那么面积大的是正文内容的可能性会更高。
时间
对于发布时间来说,也是有一些线索供提取的。
一些正规的网站同样会把时间信息放到 meta 节点内,如上述例子中就多了这样的一个 meta 节点,内容如下:
<meta name="og:time " content="2019-02-20 02:26:00">
这里我们可以看到这个 meta 节点指定了 property 为 og:time,这是一种常见写法,其内容正好就是时间的信息,通过这部分信息我们也能进行时间的提取。
但并不是所有的网页都会包含这个 meta 节点,多数情况下网站其实是没有这个节点的。
那么怎么办呢?我们知道其实时间通常都有固定的一些写法,如 2019-02-20 02:26:00,而且对于发布时间来说,其通常会包含一些关键的字符,如「发布」、「发表于」等关键字也可以作为参考依据,所以利用一些正则表达式匹配往往能起到不错的效果。
所以说,对于时间的提取,我们可以定义一些时间的正则表达式,基于某种特定的模式来提取时间信息。
这时候有人就会说了,如果这篇文章本身包含了时间,或者在侧栏或底栏部分包含了时间,那又怎么办呢?
-
对于文章本身包含时间的情况,我们可以根据上一步的结果,对正文内容对应的节点从节点列表里面删除,这样就会排除文章本身的干扰了。
-
对于侧栏或底栏部分包含了时间的情况又怎么分辨呢?这时候我们可以根据节点距离来进行计算。比如发布时间往往和正文距离较近或者紧贴着,而侧栏或底栏的时间却又分布在其他的区块,所以这些日期节点和正文节点相对较远,这样就能找到权重最高的时间节点了。
因此,综上所述,时间的提取标准有:
-
根据 meta 节点的信息进行提取。
-
根据一些正则表达式来提取。
-
根据节点和正文的距离来筛选更优节点。
作者
这个字段其实相对不太好提取,但是它的重要性相对会低一点,因此如果错误率相比其他的字段有一定的升高的话,还是能够忍受的。
还是上文所述的内容,一些标准的网站会把 author 信息也加到 meta 节点里面,所以我们可以根据这个信息来提取。
其他的情况我们同样需要根据一些固定的写法来匹配了,如一些关键字“作者”“编辑”“撰稿”,等等关键字。另外我们还可以根据一些常用的姓氏来进行一些优化和提取。
如果在提取的时候有多个候选,我们还可以利用上一步的结果,那就是和日期节点之间的距离来判断,因为一般来说,作者信息旁边大概率会有时间的相关信息,这个指标也可以成为筛选的依据。
因此,综上所述,作者的提取标准有:
-
根据 meta 节点的信息进行提取。
-
根据一些固定的关键词写法,用正则表达式来提取。
-
根据一些常用的姓氏来对提取结果进行筛选。
-
对和时间节点之间的距离进行计算,同样也可以成为筛选的依据。
总结
好了,本节我们就大体介绍了智能解析算法的提取原理,在下一节我们会用代码来实现其中的一些解析算法,下节课见。
跟我来一起实现智能化解析算法吧
在上一节课我们介绍了智能解析算法的实现原理,接下来我们就一起动手用代码来实现一下智能解析算法吧。
学习目标
这里使用的案例还是凤凰网的一篇资讯文章,链接为:http://news.ifeng.com/c/7kQcQG2peWU,本节我们主要实现的提取字段为标题、时间、正文内容。
我们会用 Python 来对上一节讲解的智能解析算法进行实现,实现新闻内容的提取。
准备工作
首先让我们将上述 URL 打开,然后在浏览器里面打开开发者工具,并打开 Elements 选项卡,最后把 HTML 代码复制下来,如图所示:
复制下来之后我们把源代码保存成一个 html 文件,名字叫作 sample.html。
然后我们定义如下代码,将 html 里面的字符转化成 lxml 里面的 HtmlElement 对象,代码如下:
from lxml.html import HtmlElement, fromstring
html = open('sample.html', encoding='utf-8').read()
element = fromstring(html=html)
这里 element 对象其实就是整个网页对应的 HtmlElement 对象,其根节点就是 html,下面我们会用到它来进行页面解析,从这个 HtmlElement 对象里面提取出我们想要的时间、标题、正文内容。
时间
对于时间来说,我们这里就根据两个方面来进行提取,一个就是 meta 标签,如果里面包含了发布时间的相关信息,一般提取出来就是对的,可信度非常高,如果提取不到,那就用正则表达式来匹配一些时间规则进行提取。
首先我们就来进行 meta 标签的提取,这里我们列出来了一些用来匹配发布时间的 XPath 规则,内容如下:
METAS = [
'//meta[starts-with(@property, "rnews:datePublished")]/@content',
'//meta[starts-with(@property, "article:published_time")]/@content',
'//meta[starts-with(@property, "og:published_time")]/@content',
'//meta[starts-with(@property, "og:release_date")]/@content',
'//meta[starts-with(@itemprop, "datePublished")]/@content',
'//meta[starts-with(@itemprop, "dateUpdate")]/@content',
'//meta[starts-with(@name, "OriginalPublicationDate")]/@content',
'//meta[starts-with(@name, "article_date_original")]/@content',
'//meta[starts-with(@name, "og:time")]/@content',
'//meta[starts-with(@name, "apub:time")]/@content',
'//meta[starts-with(@name, "publication_date")]/@content',
'//meta[starts-with(@name, "sailthru.date")]/@content',
'//meta[starts-with(@name, "PublishDate")]/@content',
'//meta[starts-with(@name, "publishdate")]/@content',
'//meta[starts-with(@name, "PubDate")]/@content',
'//meta[starts-with(@name, "pubtime")]/@content',
'//meta[starts-with(@name, "_pubtime")]/@content',
'//meta[starts-with(@name, "weibo: article:create_at")]/@content',
'//meta[starts-with(@pubdate, "pubdate")]/@content',
]
在这里我们就定义一个 extract_by_meta 的方法,它接受一个 HtmlElement 对象,定义如下:
def extract_by_meta(element: HtmlElement) -> str:
for xpath in METAS:
datetime = element.xpath(xpath)
if datetime:
return ''.join(datetime)
这里我们其实就是对 METAS 进行逐个遍历,然后查找整个 HtmlElement 里面是不是有匹配的内容,比如说:
//meta[starts-with(@property, "og:published_time")]/@content
这个就是查找 meta 节点中是不是存在以 og:published_time 开头的 property 属性,如果存在,那就提取出其中的 content 属性内容。
比如说我们的案例中刚好有一个 meta 节点,内容为:
<meta name="og:time " content="2019-02-20 02:26:00">
经过处理,它会匹配到这个 XPath 表达式:
//meta[starts-with(@name, "og:time")]/@content
这样其实 extract_by_meta 方法就成功匹配到时间信息,然后提取出 2019-02-20 02:26:00 这个值了。
这就相当于时间提取的第一步成功了,而且一般来说匹配到的结果可信度都是非常高的,我们可以直接将这个内容返回作为最终的提取结果即可。
可是并不是所有的页面都会包含这个 meta 标签,如果不包含的话,我们还需要进行第二步的提取。
下面我们再来实现第二步,也就是根据一些时间正则表达式来进行提取的方法。这里我们其实就是定义一些时间的正则表达式写法,内容如下:
REGEXES = [
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])",
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])",
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9])",
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9])",
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9]:[0-5]?[0-9])",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9]:[0-5]?[0-9])",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[0-1]?[0-9]:[0-5]?[0-9])",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[2][0-3]:[0-5]?[0-9])",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2}\s*?[1-24]\d时[0-60]\d分)([1-24]\d时)",
...
"(\d{4}[-|/|.]\d{1,2}[-|/|.]\d{1,2})",
"(\d{2}[-|/|.]\d{1,2}[-|/|.]\d{1,2})",
"(\d{4}年\d{1,2}月\d{1,2}日)",
"(\d{2}年\d{1,2}月\d{1,2}日)",
"(\d{1,2}月\d{1,2}日)"
]
由于内容比较多,这里省略了部分内容。其实这里就是一些日期的常见写法格式,由于日期的写法是有限的,所以我们通过一些有限的正则表达就能进行匹配。
接下来我们就定义一个正则搜索的方法,实现如下:
import re
def extract_by_regex(element: HtmlElement) -> str:
text = ''.join(element.xpath('.//text()'))
for regex in REGEXES:
result = re.search(regex, text)
if result:
return result.group(1)
这里我们先查找了 element 的文本内容,然后对文本内容进行正则表达式搜索,符合条件的就直接返回。
最后,时间提取的方法我们直接定义为:
extract_by_meta(element) or extract_by_regex(element)
即可,这样就会优先提取 meta,其次根据正则表达式提取。
标题
接下来我们来实现标题的提取,根据上节内容,标题的提取我们在这里实现三个来源的提取:
-
查找 meta 节点里面的标题信息。
-
查找 title 节点的标题信息。
-
查找 h 节点的信息。
首先就是从 meta 节点提取,其实过程还是类似的,我们定义如下的 meta 节点的 XPath 提取规则,内容如下:
METAS = [
'//meta[starts-with(@property, "og:title")]/@content',
'//meta[starts-with(@name, "og:title")]/@content',
'//meta[starts-with(@property, "title")]/@content',
'//meta[starts-with(@name, "title")]/@content',
'//meta[starts-with(@property, "page:title")]/@content',
]
实现的提取方法也是完全一样的:
def extract_by_meta(element: HtmlElement) -> str:
for xpath in METAS:
title = element.xpath(xpath)
if title:
return ''.join(title)
关于这一部分就不再展开说明了。
接下来我们还可以提取 title 和 h 节点的信息,通过基本的 XPath 表达式就可以实现,代码如下:
def extract_by_title(element: HtmlElement):
return ''.join(element.xpath('//title//text()')).strip()
def extract_by_h(element: HtmlElement):
return ''.join(
element.xpath('(//h1//text() | //h2//text() | //h3//text())')).strip()
这里我们提取了 title、h1~h3 节点的信息,然后返回了它们的纯文本内容。
紧接着,我们分别调用以下这三个方法,看看针对这个案例,其结果是怎样的,调用如下:
title_extracted_by_meta = extract_by_meta(element)
title_extracted_by_h = extract_by_h(element)
title_extracted_by_title = extract_by_title(element)
运行结果如下:
title_extracted_by_meta 故宫,你低调点!故宫:不,实力已不允许我继续低调
title_extracted_by_h 故宫,你低调点!故宫:不,实力已不允许我继续低调为您推荐精品有声好书精选
title_extracted_by_title 故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰网资讯_凤凰网
这里我们观察到,三个方法都返回了差不多的结果,但是后缀还是不太一样。
title_extracted_by_meta 实际上是完全正确的内容,可以直接返回,一般来说,它的可信度也非常高,如果匹配到,那就直接返回就好了。
但是如果不存在 title_extracted_by_meta 的结果呢?那只能靠 title_extracted_by_title 和 title_extracted_by_h 了。
这里我们观察到 title_extracted_by_title 和 title_extracted_by_h 包含一些冗余信息,仔细想想确实是这样的,因为 title 一般来说会再加上网站的名称,而 h 节点众多,通常会包含很多噪音。
这里我们可以提取它们的公共连续内容其实就好了,这里用到一个算法,就是最长连续公共子串,即 Longest Common String,这里我们直接借助于 Python 的 difflib 库来实现即可,如果你感兴趣的话也可以手动实现一下。
这里我们的实现如下:
from difflib import SequenceMatcher
def lcs(a, b):
match = SequenceMatcher(None, a, b).find_longest_match(0, len(a), 0, len(b))
return a[match[0]: match[0] + match[2]]
这里定义了一个 lcs 方法,它接收两个字符串类型的参数,比如 abcd 和 bcde,那么它的返回结果就是它们的公共部分,即 bcd。
好,那么对于 title_extracted_by_title 和 title_extracted_by_h,我们调用下 lcs 方法就好了,实现如下:
lcs(title_extracted_by_title, title_extracted_by_h)
最终我们可以把标题的提取定义成一个方法,实现如下:
def extract_title(element: HtmlElement):
title_extracted_by_meta = extract_by_meta(element)
title_extracted_by_h = extract_by_h(element)
title_extracted_by_title = extract_by_title(element)
if title_extracted_by_meta:
return title_extracted_by_meta
if title_extracted_by_title and title_extracted_by_h:
return lcs(title_extracted_by_title, title_extracted_by_h)
if title_extracted_by_title:
return title_extracted_by_title
return title_extracted_by_h
这里我们就定义了一些优先级判定逻辑,如:
-
如果存在 title_extracted_by_meta,由于其可信度非常高,直接返回即可。
-
如果不存在 title_extracted_by_meta,而 title_extracted_by_title 和 title_extracted_by_h 同时存在,取二者的最长公共子串返回即可。
-
如果上述条件不成立, title_extracted_by_title 存在,返回 title_extracted_by_title 即可。
-
如果上述条件不成立,只能返回 title_extracted_by_h 了。
以上就是我们的标题提取逻辑。
正文
接下来终于轮到重头戏,正文提取了。在上一节课我们介绍了利用文本密度和符号密度进行提取的方法,下面我们就来实现一下吧。
正文的提取需要我们做一些预处理工作,比如一个 html 标签内有很多噪音,非常影响正文的提取,比如说 script、style 这些内容,一定不会包含正文,但是它们会严重影响文本密度的计算,所以这里我们先定义一个预处理操作。
from lxml.html import HtmlElement, etree
CONTENT_USELESS_TAGS = ['meta', 'style', 'script', 'link', 'video', 'audio', 'iframe', 'source', 'svg', 'path',
'symbol', 'img']
CONTENT_STRIP_TAGS = ['span', 'blockquote']
CONTENT_NOISE_XPATHS = [
'//div[contains(@class, "comment")]',
'//div[contains(@class, "advertisement")]',
'//div[contains(@class, "advert")]',
'//div[contains(@style, "display: none")]',
]
def preprocess4content(element: HtmlElement):
# remove tag and its content
etree.strip_elements(element, *CONTENT_USELESS_TAGS)
# only move tag pair
etree.strip_tags(element, *CONTENT_STRIP_TAGS)
# remove noise tags
remove_children(element, CONTENT_NOISE_XPATHS)
for child in children(element):
# merge text in span or strong to parent p tag
if child.tag.lower() == 'p':
etree.strip_tags(child, 'span')
etree.strip_tags(child, 'strong')
if not (child.text and child.text.strip()):
remove_element(child)
# if a div tag does not contain any sub node, it could be converted to p node.
if child.tag.lower() == 'div' and not child.getchildren():
child.tag = 'p'
这里我们定义了一些规则,比如 CONTENT_USELESS_TAGS 代表一些噪音节点,可以直接调用 strip_elements 把整个节点和它的内容删除。
另外定义了 CONTENT_STRIP_TAGS ,这些节点文本内容需要保留,但是它的标签是可以删掉的。
另外我们还定义了 CONTENT_NOISE_XPATHS,这是一些很明显不是正文的节点,如评论、广告等,直接移除就好。
这里还依赖于几个工具方法,定义如下:
def remove_element(element: HtmlElement):
parent = element.getparent()
if parent is not None:
parent.remove(element)
def remove_children(element: HtmlElement, xpaths=None):
if not xpaths:
return
for xpath in xpaths:
nodes = element.xpath(xpath)
for node in nodes:
remove_element(node)
return element
def children(element: HtmlElement):
yield element
for child_element in element:
if isinstance(child_element, HtmlElement):
yield from children(child_element)
另外对于一些节点我们还做了特殊处理,如 p 节点内部的 span、strong 节点去掉标签,只留内容。如果是 div 节点,而且没有子节点了,那么可以换成 p 节点。
当然还有一些细节的处理,你如果想到了可以继续优化。预处理完毕之后,整个 element 就比较规整了,去除了很多噪声和干扰数据。
接下来我们就来实现文本密度和符号密度的计算吧。为了方便处理,这里我把节点定义成了一个 Python Object,名字叫作 ElementInfo,它里面有很多字段,代表了某一个节点的信息,比如文本密度、符号密度等,定义如下:
from lxml.html import HtmlElement
from pydantic import BaseModel
class ElementInfo(BaseModel):
id: int = None
tag_name: str = None
element: HtmlElement = None
number_of_char: int = 0
number_of_linked_char: int = 0
number_of_tag: int = 0
number_of_linked_tag: int = 0
number_of_p_tag: int = 0
number_of_punctuation: int = 0
density_of_punctuation: int = 1
density_of_text: int = 0
density_score: int = 0
class Config:
arbitrary_types_allowed = True
这里我们定义了几个字段。
-
id:节点的唯一 id。
-
tag_name:节点的标签值,如 p、div、img 等。
-
element:节点对应的 HtmlElement 对象。
-
number_of_char:节点的总字符数。
-
number_of_linked_char:节点带超链接的字符数。
-
number_of_tag:节点的标签数。
-
number_of_linked_tag:节点的带链接的标签数,即 a 的标签数。
-
number_of_p_tag:节点的 p 标签数。
-
number_of_punctuation:节点包含的标点符号数。
-
density_of_punctuation:节点的符号密度。
-
density_of_text:节点的文本密度。
-
density_score:最终评分。
好,下面我们要做的就是对整个 HTML 的所有节点进行处理,然后得到每个节点的信息,实现如下:
# start to evaluate every child element
element_infos = []
child_elements = children_of_body(element)
for child_element in child_elements:
# new element info
element_info = ElementInfo()
element_info.element = child_element
element_info = fill_element_info(element_info)
element_infos.append(element_info)
这里我们先调用了 children_of_body 获取了最初 element 节点的所有子节点,然后对节点进行处理。
其中这里依赖 children_of_body 和 fill_element_info 方法,分别是获取所有 body 内的子节点(包括 body)以及计算节点信息,实现如下:
def children_of_body(element: HtmlElement):
body_xpath = '//body'
elements = element.xpath(body_xpath)
if elements:
return children(elements[0])
return []
def fill_element_info(element_info: ElementInfo):
element = element_info.element
# fill id
element_info.id = hash(element)
element_info.tag_name = element.tag
# fill number_of_char
element_info.number_of_char = number_of_char(element)
element_info.number_of_linked_char = number_of_linked_char(element)
element_info.number_of_tag = number_of_tag(element)
element_info.number_of_linked_tag = number_of_linked_tag(element)
element_info.number_of_p_tag = number_of_p_tag(element)
element_info.number_of_punctuation = number_of_punctuation(element)
# fill density
element_info.density_of_text = density_of_text(element_info)
element_info.density_of_punctuation = density_of_punctuation(element_info)
return element_info
这里 fill_element_info 方法非常重要,其实就是填充了 element_info 的几乎所有指标信息,这里又依赖了 number_of_char、number_of_linked_char、number_of_tag、number_of_linked_tag、number_of_p_tag、number_of_punctuation、density_of_text、density_of_punctuation 方法,实现如下:
def number_of_char(element: HtmlElement):
text = ''.join(element.xpath('.//text()'))
text = re.sub(r'\s*', '', text, flags=re.S)
return len(text)
def number_of_linked_char(element: HtmlElement):
text = ''.join(element.xpath('.//a//text()'))
text = re.sub(r'\s*', '', text, flags=re.S)
return len(text)
def number_of_tag(element: HtmlElement):
return len(element.xpath('.//*'))
def number_of_p_tag(element: HtmlElement):
return len(element.xpath('.//p'))
def number_of_linked_tag(element: HtmlElement):
return len(element.xpath('.//a'))
def density_of_text(element_info: ElementInfo):
# if denominator is 0, just return 0
if element_info.number_of_tag - element_info.number_of_linked_tag == 0:
return 0
return (element_info.number_of_char - element_info.number_of_linked_char) / \
(element_info.number_of_tag - element_info.number_of_linked_tag)
def density_of_punctuation(element_info: ElementInfo):
result = (element_info.number_of_char - element_info.number_of_linked_char) / \
(element_info.number_of_punctuation + 1)
# result should not be zero
return result or 1
def number_of_punctuation(element: HtmlElement):
text = ''.join(element.xpath('.//text()'))
text = re.sub(r'\s*', '', text, flags=re.S)
punctuations = [c for c in text if c in PUNCTUATION]
return len(punctuations)
这里比较重要的就是 density_of_text 和 density_of_punctuation 两个方法了,分别代表文本密度和符号密度,其算法原理在上一节已经提到了,可以参考论文《洪鸿辉,等 基于文本富豪密度的网页正文提取方法》的内容。
好,这样我们运行完毕之后,就可以得到每个节点的各个指标啦。最后,我们继续参考论文《洪鸿辉,等 基于文本富豪密度的网页正文提取方法》的公式,根据各个指标计算每个节点的得分情况,最后提取内容即可:
import numpy as np
# start to evaluate every child element
element_infos = []
child_elements = children_of_body(element)
for child_element in child_elements:
# new element info
element_info = ElementInfo()
element_info.element = child_element
element_info = fill_element_info(element_info)
element_infos.append(element_info)
# get std of density_of_text among all elements
density_of_text = [element_info.density_of_text for element_info in element_infos]
density_of_text_std = np.std(density_of_text, ddof=1)
# get density_score of every element
for element_info in element_infos:
score = np.log(density_of_text_std) * \
element_info.density_of_text * \
np.log10(element_info.number_of_p_tag + 2) * \
np.log(element_info.density_of_punctuation)
element_info.density_score = score
# sort element info by density_score
element_infos = sorted(element_infos, key=lambda x: x.density_score, reverse=True)
element_info_first = element_infos[0] if element_infos else None
text = '\n'.join(element_info_first.element.xpath('.//p//text()'))
这里我们首先计算了 density_of_text 的标准差,然后对各个节点计算了最终的密度得分,最后排序得到最高的节点,获取文本值即可。
运行结果如下:
"“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“重檐之上的月光,曾照进古人的宫殿;城墙上绵延的灯彩,映出了角楼的瑰丽。今夜,一群博物馆人将我点一段话。\n半小时后,“紫禁城上元之夜”的灯光点亮了北京夜空。\n午门城楼及东西雁翅楼用白、黄、红三种颜色光源装扮!\n太和门广场变成了超大的夜景灯光秀场!\n图片来源:东方IC 版权作品 请勿转载\n午门城宫博物院供图\n故宫的角楼被灯光装点出满满的节日气氛!\n故宫博物院供图\n令人惊叹的是,故宫的“网红”藏品《清明上河图》《千里江山图卷》在“灯会”中展开画卷。\n灯光版《清明上河图》\n以灯为笔,以屋顶为,故宫博物院最北端神武门也被灯光点亮!\n故宫博物院供图\n上元之夜,故宫邀请了劳动模范、北京榜样、快递小哥、环卫工人、解放军和武警官兵、消防指战员、公安干警等各界代表以及预约成功的观众,共3000人故宫博物院供图\n时间退回到两天前,故宫博物院发布了2月19日(正月十五)、20日(正月十六)即将举办“紫禁城上元之夜”文化活动的消息。\n图片来源:视觉中国\n18日凌晨,一众网友前往故宫博物院官网抢票,网站甚节就有诸多讲究。\n有灯无月不娱人,有月无灯不算春。\n春到人间人似玉,灯烧月下月如怠。\n满街珠翠游村女,沸地笙歌赛社神。\n不展芳尊开口笑,如何消得此良辰。\n——唐伯虎《元宵》\n明代宫中过上元节,皇宵节晚会”。\n2月18日,北京故宫午门调试灯光。中新社记者 杜洋 摄\n其中,灯戏颇为有趣。由多人舞灯拼出吉祥文字及图案,每人手执彩灯、身着不同颜色的服装,翩翩起舞,类似于现代的大型团体操表演。\n但这紫禁城,恭亲王奕 与英法联军交换了《天津条约》批准书,并订立《中英北京条约》《中法北京条约》作为补充。\n战争结束了,侵略者摇身一变成了游客。一位外国“摄影师”拍下了当年的紫禁城,并在日记里写到,百年。\n直到上世纪40年代时,故宫的环境仍然并不是想象中的博物馆的状态。\n曾有故宫博物院工作人员撰文回忆,当时的故宫内杂草丛生,房倒屋漏,有屋顶竟长出了树木。光是清理当时宫中存留的垃圾、杂草就用单霁翔到任故宫院长。那时,他拿到的故宫博物院介绍,写了这座博物馆诸多的“世界之最”。\n可他觉得,当自己真正走到观众中间,这些“世界之最”都没有了。\n2月18日,北京故宫午门调试灯光。中新社记者 杜洋 摄外环境进行了大整治。\n游客没有地方休息,那就拆除了宫中的临时建筑、新增供游客休息的椅子;\n游客排队上厕所,那就将一个职工食堂都改成了洗手间;\n游客买票难,那就全面采用电子购票,新增多个售票点;馆。\n今年,持续整个正月的“过大年”展览和“紫禁城上元之夜”,让本该是淡季的故宫变得一票难求。\n在不少普通人眼中,近600岁的故宫正变得越来越年轻。\n资料图:故宫博物院院长单霁翔。中新社记者 刘关关 摄元宵节活动进行评估后,或结合二十四节气等重要时间节点推出夜场活动。\n你期待吗?\n作者:上官云 宋宇晟"
可以看到,正文就被成功提取出来了。
整理
最后整理一下,三者结果合并,输出为 JSON 格式,实现如下:
def extract(html):
return {
'title': extract_title(html),
'datetime': extract_datetime(html),
'content': extract_content(html)
}
最后,我们可以看到类似的输出效果,内容如下:
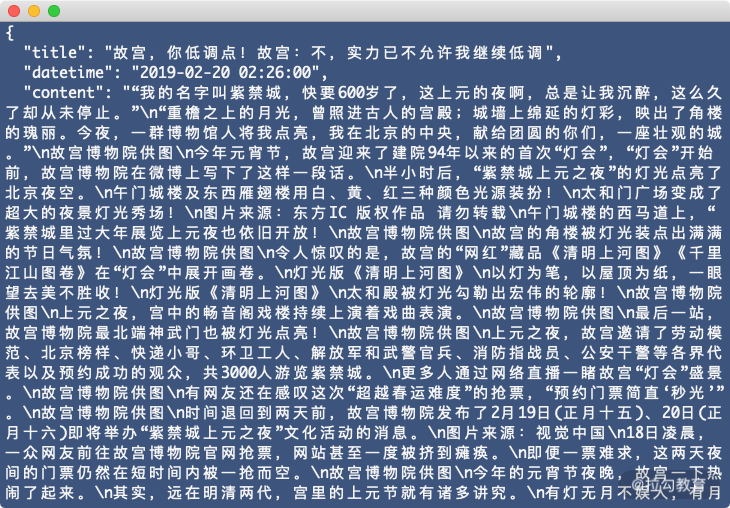
到此为止,我们就成功提取出来了标题、时间和正文内容并输出为 JSON 格式了。其他的一些字段相对没有那么重要,你可以根据类似的方法来进行提取和实验。
