资料
异步爬虫的原理和解析
我们知道爬虫是 IO 密集型任务,比如如果我们使用 requests 库来爬取某个站点的话,发出一个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何的事情。对于这种情况我们有没有优化方案呢?
实例引入
比如在这里我们看这么一个示例网站:https://static4.scrape.center/,如图所示。
这个网站在内部实现返回响应的逻辑的时候特意加了 5 秒的延迟,也就是说如果我们用 requests 来爬取其中某个页面的话,至少需要 5 秒才能得到响应。
另外这个网站的逻辑结构在之前的案例中我们也分析过,其内容就是电影数据,一共 100 部,每个电影的详情页是一个自增 ID,从 1~100,比如 https://static4.scrape.center/detail/43 就代表第 43 部电影,如图所示。
下面我们来用 requests 写一个遍历程序,直接遍历 1~100 部电影数据,代码实现如下:
import requests
import logging
import time
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
TOTAL_NUMBER = 100
BASE_URL = 'https://static4.scrape.center/detail/{id}'
start_time = time.time()
for id in range(1, TOTAL_NUMBER + 1):
url = BASE_URL.format(id=id)
logging.info('scraping %s', url)
response = requests.get(url)
end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)
这里我们直接用循环的方式构造了 100 个详情页的爬取,使用的是 requests 单线程,在爬取之前和爬取之后记录下时间,最后输出爬取了 100 个页面消耗的时间。
运行结果如下:
2020-03-31 14:40:35,411 - INFO: scraping https://static4.scrape.center/detail/1
2020-03-31 14:40:40,578 - INFO: scraping https://static4.scrape.center/detail/2
2020-03-31 14:40:45,658 - INFO: scraping https://static4.scrape.center/detail/3
2020-03-31 14:40:50,761 - INFO: scraping https://static4.scrape.center/detail/4
2020-03-31 14:40:55,852 - INFO: scraping https://static4.scrape.center/detail/5
2020-03-31 14:41:00,956 - INFO: scraping https://static4.scrape.center/detail/6
...
2020-03-31 14:48:58,785 - INFO: scraping https://static4.scrape.center/detail/99
2020-03-31 14:49:03,867 - INFO: scraping https://static4.scrape.center/detail/100
2020-03-31 14:49:09,042 - INFO: total time 513.6309871673584 seconds
2020-03-31 14:49:09,042 - INFO: total time 513.6309871673584 seconds
由于每个页面都至少要等待 5 秒才能加载出来,因此 100 个页面至少要花费 500 秒的时间,总的爬取时间最终为 513.6 秒,将近 9 分钟。
这个在实际情况下是很常见的,有些网站本身加载速度就比较慢,稍慢的可能 1~3 秒,更慢的说不定 10 秒以上才可能加载出来。如果我们用 requests 单线程这么爬取的话,总的耗时是非常多的。此时如果我们开了多线程或多进程来爬取的话,其爬取速度确实会成倍提升,但有没有更好的解决方案呢?
本课时我们就来了解一下使用异步执行方式来加速的方法,此种方法对于 IO 密集型任务非常有效。如将其应用到网络爬虫中,爬取效率甚至可以成百倍地提升。
基本了解
在了解异步协程之前,我们首先得了解一些基础概念,如阻塞和非阻塞、同步和异步、多进程和协程。
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。
常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正处理事情,它们也会被阻塞。如果是多核 CPU 则正在执行上下文切换操作的核不可被利用。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。
非阻塞并不是在任何程序级别、任何情况下都可以存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。
非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。
例如购物系统中更新商品库存,需要用“行锁”作为通信信号,让不同的更新请求强制排队顺序执行,那更新库存的操作是同步的。
简言之,同步意味着有序。
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定。
简言之,异步意味着无序。
多进程
多进程就是利用 CPU 的多核优势,在同一时间并行地执行多个任务,可以大大提高执行效率。
协程
协程,英文叫作 Coroutine,又称微线程、纤程,协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。
协程本质上是个单进程,协程相对于多进程来说,无需线程上下文切换的开销,无需原子操作锁定及同步的开销,编程模型也非常简单。
我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定的时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他的事情,等到响应得到之后才切换回来继续处理,这样可以充分利用 CPU 和其他资源,这就是协程的优势。
协程用法
接下来,我们来了解下协程的实现,从 Python 3.4 开始,Python 中加入了协程的概念,但这个版本的协程还是以生成器对象为基础的,在 Python 3.5 则增加了 async/await,使得协程的实现更加方便。
Python 中使用协程最常用的库莫过于 asyncio,所以本文会以 asyncio 为基础来介绍协程的使用。
首先我们需要了解下面几个概念。
-
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。
-
coroutine:中文翻译叫协程,在 Python 中常指代为协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。
-
task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。
-
future:代表将来执行或没有执行的任务的结果,实际上和 task 没有本质区别。
另外我们还需要了解 async/await 关键字,它是从 Python 3.5 才出现的,专门用于定义协程。其中,async 定义一个协程,await 用来挂起阻塞方法的执行。
定义协程
首先我们来定义一个协程,体验一下它和普通进程在实现上的不同之处,代码如下:
import asyncio
async def execute(x):
print('Number:', x)
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
loop = asyncio.get_event_loop()
loop.run_until_complete(coroutine)
print('After calling loop')
运行结果:
Coroutine: <coroutine object execute at 0x1034cf830>
After calling execute
Number: 1
After calling loop
首先我们引入了 asyncio 这个包,这样我们才可以使用 async 和 await,然后我们使用 async 定义了一个 execute 方法,方法接收一个数字参数,方法执行之后会打印这个数字。
随后我们直接调用了这个方法,然而这个方法并没有执行,而是返回了一个 coroutine 协程对象。随后我们使用 get_event_loop 方法创建了一个事件循环 loop,并调用了 loop 对象的 run_until_complete 方法将协程注册到事件循环 loop 中,然后启动。最后我们才看到了 execute 方法打印了输出结果。
可见,async 定义的方法就会变成一个无法直接执行的 coroutine 对象,必须将其注册到事件循环中才可以执行。
上面我们还提到了 task,它是对 coroutine 对象的进一步封装,它里面相比 coroutine 对象多了运行状态,比如 running、finished 等,我们可以用这些状态来获取协程对象的执行情况。
在上面的例子中,当我们将 coroutine 对象传递给 run_until_complete 方法的时候,实际上它进行了一个操作就是将 coroutine 封装成了 task 对象,我们也可以显式地进行声明,如下所示:
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
loop = asyncio.get_event_loop()
task = loop.create_task(coroutine)
print('Task:', task)
loop.run_until_complete(task)
print('Task:', task)
print('After calling loop')
运行结果:
Coroutine: <coroutine object execute at 0x10e0f7830>
After calling execute
Task: <Task pending coro=<execute() running at demo.py:4>>
Number: 1
Task: <Task finished coro=<execute() done, defined at demo.py:4> result=1>
After calling loop
这里我们定义了 loop 对象之后,接着调用了它的 create_task 方法将 coroutine 对象转化为了 task 对象,随后我们打印输出一下,发现它是 pending 状态。接着我们将 task 对象添加到事件循环中得到执行,随后我们再打印输出一下 task 对象,发现它的状态就变成了 finished,同时还可以看到其 result 变成了 1,也就是我们定义的 execute 方法的返回结果。
另外定义 task 对象还有一种方式,就是直接通过 asyncio 的 ensure_future 方法,返回结果也是 task 对象,这样的话我们就可以不借助于 loop 来定义,即使我们还没有声明 loop 也可以提前定义好 task 对象,写法如下:
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(1)
print('Coroutine:', coroutine)
print('After calling execute')
task = asyncio.ensure_future(coroutine)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
print('After calling loop')
运行结果:
Coroutine: <coroutine object execute at 0x10aa33830>
After calling execute
Task: <Task pending coro=<execute() running at demo.py:4>>
Number: 1
Task: <Task finished coro=<execute() done, defined at demo.py:4> result=1>
After calling loop
发现其运行效果都是一样的。
绑定回调
另外我们也可以为某个 task 绑定一个回调方法,比如我们来看下面的例子:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
def callback(task):
print('Status:', task.result())
coroutine = request()
task = asyncio.ensure_future(coroutine)
task.add_done_callback(callback)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
在这里我们定义了一个 request 方法,请求了百度,获取其状态码,但是这个方法里面我们没有任何 print 语句。随后我们定义了一个 callback 方法,这个方法接收一个参数,是 task 对象,然后调用 print 方法打印了 task 对象的结果。这样我们就定义好了一个 coroutine 对象和一个回调方法,我们现在希望的效果是,当 coroutine 对象执行完毕之后,就去执行声明的 callback 方法。
那么它们二者怎样关联起来呢?很简单,只需要调用 add_done_callback 方法即可,我们将 callback 方法传递给了封装好的 task 对象,这样当 task 执行完毕之后就可以调用 callback 方法了,同时 task 对象还会作为参数传递给 callback 方法,调用 task 对象的 result 方法就可以获取返回结果了。
运行结果:
Task: <Task pending coro=<request() running at demo.py:5> cb=[callback() at demo.py:11]>
Status: <Response [200]>
Task: <Task finished coro=<request() done, defined at demo.py:5> result=<Response [200]>>
实际上不用回调方法,直接在 task 运行完毕之后也可以直接调用 result 方法获取结果,如下所示:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
coroutine = request()
task = asyncio.ensure_future(coroutine)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
print('Task Result:', task.result())
运行结果是一样的:
Task: <Task pending coro=<request() running at demo.py:4>>
Task: <Task finished coro=<request() done, defined at demo.py:4> result=<Response [200]>>
Task Result: <Response [200]>
多任务协程
上面的例子我们只执行了一次请求,如果我们想执行多次请求应该怎么办呢?我们可以定义一个 task 列表,然后使用 asyncio 的 wait 方法即可执行,看下面的例子:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
tasks = [asyncio.ensure_future(request()) for _ in range(5)]
print('Tasks:', tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print('Task Result:', task.result())
这里我们使用一个 for 循环创建了五个 task,组成了一个列表,然后把这个列表首先传递给了 asyncio 的 wait() 方法,然后再将其注册到时间循环中,就可以发起五个任务了。最后我们再将任务的运行结果输出出来,运行结果如下:
Tasks: [<Task pending coro=<request() running at demo.py:5>>,
<Task pending coro=<request() running at demo.py:5>>,
<Task pending coro=<request() running at demo.py:5>>,
<Task pending coro=<request() running at demo.py:5>>,
<Task pending coro=<request() running at demo.py:5>>]
Task Result: <Response [200]>
Task Result: <Response [200]>
Task Result: <Response [200]>
Task Result: <Response [200]>
Task Result: <Response [200]>
可以看到五个任务被顺次执行了,并得到了运行结果。
协程实现
前面讲了这么多,又是 async,又是 coroutine,又是 task,又是 callback,但似乎并没有看出协程的优势啊?反而写法上更加奇怪和麻烦了,别急,上面的案例只是为后面的使用作铺垫,接下来我们正式来看下协程在解决 IO 密集型任务上有怎样的优势吧!
上面的代码中,我们用一个网络请求作为示例,这就是一个耗时等待的操作,因为我们请求网页之后需要等待页面响应并返回结果。耗时等待的操作一般都是 IO 操作,比如文件读取、网络请求等等。协程对于处理这种操作是有很大优势的,当遇到需要等待的情况的时候,程序可以暂时挂起,转而去执行其他的操作,从而避免一直等待一个程序而耗费过多的时间,充分利用资源。
为了表现出协程的优势,我们还是拿本课时开始介绍的网站 https://static4.scrape.center/ 为例来进行演示,因为该网站响应比较慢,所以我们可以通过爬取时间来直观地感受到爬取速度的提升。
为了让你更好地理解协程的正确使用方法,这里我们先来看看使用协程时常犯的错误,后面再给出正确的例子来对比一下。
首先,我们还是拿之前的 requests 来进行网页请求,接下来我们再重新使用上面的方法请求一遍:
import asyncio
import requests
import time
start = time.time()
async def request():
url = 'https://static4.scrape.center/'
print('Waiting for', url)
response = requests.get(url)
print('Get response from', url, 'response', response)
tasks = [asyncio.ensure_future(request()) for _ in range(10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Cost time:', end - start)
在这里我们还是创建了 10 个 task,然后将 task 列表传给 wait 方法并注册到时间循环中执行。
运行结果如下:
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
...
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Cost time: 51.422438859939575
可以发现和正常的请求并没有什么两样,依然还是顺次执行的,耗时 51 秒,平均一个请求耗时 5 秒,说好的异步处理呢?
其实,要实现异步处理,我们得先要有挂起的操作,当一个任务需要等待 IO 结果的时候,可以挂起当前任务,转而去执行其他任务,这样我们才能充分利用好资源,上面方法都是一本正经的串行走下来,连个挂起都没有,怎么可能实现异步?想太多了。
要实现异步,接下来我们需要了解一下 await 的用法,使用 await 可以将耗时等待的操作挂起,让出控制权。当协程执行的时候遇到 await,时间循环就会将本协程挂起,转而去执行别的协程,直到其他的协程挂起或执行完毕。
所以,我们可能会将代码中的 request 方法改成如下的样子:
async def request():
url = 'https://static4.scrape.center/'
print('Waiting for', url)
response = await requests.get(url)
print('Get response from', url, 'response', response)
仅仅是在 requests 前面加了一个 await,然而执行以下代码,会得到如下报错:
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
...
Task exception was never retrieved
future: <Task finished coro=<request() done, defined at demo.py:8> exception=TypeError("object Response can't be used in 'await' expression")>
Traceback (most recent call last):
File "demo.py", line 11, in request
response = await requests.get(url)
TypeError: object Response can't be used in 'await' expression
这次它遇到 await 方法确实挂起了,也等待了,但是最后却报了这么个错,这个错误的意思是 requests 返回的 Response 对象不能和 await 一起使用,为什么呢?因为根据官方文档说明,await 后面的对象必须是如下格式之一:
-
A native coroutine object returned from a native coroutine function,一个原生 coroutine 对象。
-
A generator-based coroutine object returned from a function decorated with types.coroutine,一个由 types.coroutine 修饰的生成器,这个生成器可以返回 coroutine 对象。
-
An object with an __await__ method returning an iterator,一个包含 __await__ 方法的对象返回的一个迭代器。
可以参见:https://www.python.org/dev/peps/pep-0492/#await-expression。
requests 返回的 Response 不符合上面任一条件,因此就会报上面的错误了。
那么你可能会发现,既然 await 后面可以跟一个 coroutine 对象,那么我用 async 把请求的方法改成 coroutine 对象不就可以了吗?所以就改写成如下的样子:
import asyncio
import requests
import time
start = time.time()
async def get(url):
return requests.get(url)
async def request():
url = 'https://static4.scrape.center/'
print('Waiting for', url)
response = await get(url)
print('Get response from', url, 'response', response)
tasks = [asyncio.ensure_future(request()) for _ in range(10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Cost time:', end - start)
这里我们将请求页面的方法独立出来,并用 async 修饰,这样就得到了一个 coroutine 对象,我们运行一下看看:
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
...
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <Response [200]>
Cost time: 51.394437756259273
还是不行,它还不是异步执行,也就是说我们仅仅将涉及 IO 操作的代码封装到 async 修饰的方法里面是不可行的!我们必须要使用支持异步操作的请求方式才可以实现真正的异步,所以这里就需要 aiohttp 派上用场了。
使用 aiohttp
aiohttp 是一个支持异步请求的库,利用它和 asyncio 配合我们可以非常方便地实现异步请求操作。
安装方式如下:
pip3 install aiohttp
官方文档链接为:https://aiohttp.readthedocs.io/,它分为两部分,一部分是 Client,一部分是 Server,详细的内容可以参考官方文档。
下面我们将 aiohttp 用上来,将代码改成如下样子:
import asyncio
import aiohttp
import time
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
response = await session.get(url)
await response.text()
await session.close()
return response
async def request():
url = 'https://static4.scrape.center/'
print('Waiting for', url)
response = await get(url)
print('Get response from', url, 'response', response)
tasks = [asyncio.ensure_future(request()) for _ in range(10)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Cost time:', end - start)
在这里我们将请求库由 requests 改成了 aiohttp,通过 aiohttp 的 ClientSession 类的 get 方法进行请求,结果如下:
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Waiting for https://static4.scrape.center/
Get response from https://static4.scrape.center/ response <ClientResponse(https://static4.scrape.center/) [200 OK]>
<CIMultiDictProxy('Server': 'nginx/1.17.8', 'Date': 'Tue, 31 Mar 2020 09:35:43 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'X-Frame-Options': 'SAMEORIGIN', 'Strict-Transport-Security': 'max-age=15724800; includeSubDomains', 'Content-Encoding': 'gzip')>
...
Get response from https://static4.scrape.center/ response <ClientResponse(https://static4.scrape.center/) [200 OK]>
<CIMultiDictProxy('Server': 'nginx/1.17.8', 'Date': 'Tue, 31 Mar 2020 09:35:44 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Vary': 'Accept-Encoding', 'X-Frame-Options': 'SAMEORIGIN', 'Strict-Transport-Security': 'max-age=15724800; includeSubDomains', 'Content-Encoding': 'gzip')>
Cost time: 6.1102519035339355
成功了!我们发现这次请求的耗时由 51 秒变直接成了 6 秒,耗费时间减少了非常非常多。
代码里面我们使用了 await,后面跟了 get 方法,在执行这 10 个协程的时候,如果遇到了 await,那么就会将当前协程挂起,转而去执行其他的协程,直到其他的协程也挂起或执行完毕,再进行下一个协程的执行。
开始运行时,时间循环会运行第一个 task,针对第一个 task 来说,当执行到第一个 await 跟着的 get 方法时,它被挂起,但这个 get 方法第一步的执行是非阻塞的,挂起之后立马被唤醒,所以立即又进入执行,创建了 ClientSession 对象,接着遇到了第二个 await,调用了 session.get 请求方法,然后就被挂起了,由于请求需要耗时很久,所以一直没有被唤醒。
当第一个 task 被挂起了,那接下来该怎么办呢?事件循环会寻找当前未被挂起的协程继续执行,于是就转而执行第二个 task 了,也是一样的流程操作,直到执行了第十个 task 的 session.get 方法之后,全部的 task 都被挂起了。所有 task 都已经处于挂起状态,怎么办?只好等待了。5 秒之后,几个请求几乎同时都有了响应,然后几个 task 也被唤醒接着执行,输出请求结果,最后总耗时,6 秒!
怎么样?这就是异步操作的便捷之处,当遇到阻塞式操作时,任务被挂起,程序接着去执行其他的任务,而不是傻傻地等待,这样可以充分利用 CPU 时间,而不必把时间浪费在等待 IO 上。
你可能会说,既然这样的话,在上面的例子中,在发出网络请求后,既然接下来的 5 秒都是在等待的,在 5 秒之内,CPU 可以处理的 task 数量远不止这些,那么岂不是我们放 10 个、20 个、50 个、100 个、1000 个 task 一起执行,最后得到所有结果的耗时不都是差不多的吗?因为这几个任务被挂起后都是一起等待的。
理论来说确实是这样的,不过有个前提,那就是服务器在同一时刻接受无限次请求都能保证正常返回结果,也就是服务器无限抗压,另外还要忽略 IO 传输时延,确实可以做到无限 task 一起执行且在预想时间内得到结果。但由于不同服务器处理的实现机制不同,可能某些服务器并不能承受这么高的并发,因此响应速度也会减慢。
在这里我们以百度为例,来测试下并发数量为 1、3、5、10、...、500 的情况下的耗时情况,代码如下:
import asyncio
import aiohttp
import time
def test(number):
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
response = await session.get(url)
await response.text()
await session.close()
return response
async def request():
url = 'https://www.baidu.com/'
await get(url)
tasks = [asyncio.ensure_future(request()) for _ in range(number)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Number:', number, 'Cost time:', end - start)
for number in [1, 3, 5, 10, 15, 30, 50, 75, 100, 200, 500]:
test(number)
运行结果如下:
Number: 1 Cost time: 0.05885505676269531
Number: 3 Cost time: 0.05773782730102539
Number: 5 Cost time: 0.05768704414367676
Number: 10 Cost time: 0.15174412727355957
Number: 15 Cost time: 0.09603095054626465
Number: 30 Cost time: 0.17843103408813477
Number: 50 Cost time: 0.3741800785064697
Number: 75 Cost time: 0.2894289493560791
Number: 100 Cost time: 0.6185381412506104
Number: 200 Cost time: 1.0894129276275635
Number: 500 Cost time: 1.8213098049163818
可以看到,即使我们增加了并发数量,但在服务器能承受高并发的前提下,其爬取速度几乎不太受影响。
综上所述,使用了异步请求之后,我们几乎可以在相同的时间内实现成百上千倍次的网络请求,把这个运用在爬虫中,速度提升是非常可观的。
总结
以上便是 Python 中协程的基本原理和用法,在后面一课时会详细介绍 aiohttp 的使用和爬取实战,实现快速高并发的爬取。
本节代码:https://github.com/Python3WebSpider/AsyncTest。
aiohttp异步爬虫实战
在上一课时我们介绍了异步爬虫的基本原理和 asyncio 的基本用法,另外在最后简单提及了 aiohttp 实现网页爬取的过程,这一可是我们来介绍一下 aiohttp 的常见用法,以及通过一个实战案例来介绍下使用 aiohttp 完成网页异步爬取的过程。
aiohttp
前面介绍的 asyncio 模块内部实现了对 TCP、UDP、SSL 协议的异步操作,但是对于 HTTP 请求的异步操作来说,我们就需要用到 aiohttp 来实现了。
aiohttp 是一个基于 asyncio 的异步 HTTP 网络模块,它既提供了服务端,又提供了客户端。其中我们用服务端可以搭建一个支持异步处理的服务器,用于处理请求并返回响应,类似于 Django、Flask、Tornado 等一些 Web 服务器。而客户端我们就可以用来发起请求,就类似于 requests 来发起一个 HTTP 请求然后获得响应,但 requests 发起的是同步的网络请求,而 aiohttp 则发起的是异步的。
本课时我们就主要来了解一下 aiohttp 客户端部分的使用。
基本使用
基本实例
首先我们来看一个基本的 aiohttp 请求案例,代码如下:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text(), response.status
async def main():
async with aiohttp.ClientSession() as session:
html, status = await fetch(session, 'https://cuiqingcai.com')
print(f'html: {html[:100]}...')
print(f'status: {status}')
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
在这里我们使用 aiohttp 来爬取了我的个人博客,获得了源码和响应状态码并输出,运行结果如下:
html: <!DOCTYPE HTML>
<html>
<head>
<meta charset="UTF-8">
<meta name="baidu-tc-verification" content=...
status: 200
这里网页源码过长,只截取输出了一部分,可以看到我们成功获取了网页的源代码及响应状态码 200,也就完成了一次基本的 HTTP 请求,即我们成功使用 aiohttp 通过异步的方式进行了网页的爬取,当然这个操作用之前我们所讲的 requests 同样也可以做到。
我们可以看到其请求方法的定义和之前有了明显的区别,主要有如下几点:
-
首先在导入库的时候,我们除了必须要引入 aiohttp 这个库之外,还必须要引入 asyncio 这个库,因为要实现异步爬取需要启动协程,而协程则需要借助于 asyncio 里面的事件循环来执行。除了事件循环,asyncio 里面也提供了很多基础的异步操作。
-
异步爬取的方法的定义和之前有所不同,在每个异步方法前面统一要加 async 来修饰。
-
with as 语句前面同样需要加 async 来修饰,在 Python 中,with as 语句用于声明一个上下文管理器,能够帮我们自动分配和释放资源,而在异步方法中,with as 前面加上 async 代表声明一个支持异步的上下文管理器。
-
对于一些返回 coroutine 的操作,前面需要加 await 来修饰,如 response 调用 text 方法,查询 API 可以发现其返回的是 coroutine 对象,那么前面就要加 await;而对于状态码来说,其返回值就是一个数值类型,那么前面就不需要加 await。所以,这里可以按照实际情况处理,参考官方文档说明,看看其对应的返回值是怎样的类型,然后决定加不加 await 就可以了。
-
最后,定义完爬取方法之后,实际上是 main 方法调用了 fetch 方法。要运行的话,必须要启用事件循环,事件循环就需要使用 asyncio 库,然后使用 run_until_complete 方法来运行。
注意在 Python 3.7 及以后的版本中,我们可以使用 asyncio.run(main()) 来代替最后的启动操作,不需要显式声明事件循环,run 方法内部会自动启动一个事件循环。但这里为了兼容更多的 Python 版本,依然还是显式声明了事件循环。
URL 参数设置
对于 URL 参数的设置,我们可以借助于 params 参数,传入一个字典即可,示例如下:
import aiohttp
import asyncio
async def main():
params = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.get('https://httpbin.org/get', params=params) as response:
print(await response.text())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果如下:
{
"args": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Python/3.7 aiohttp/3.6.2",
"X-Amzn-Trace-Id": "Root=1-5e85eed2-d240ac90f4dddf40b4723ef0"
},
"origin": "17.20.255.122",
"url": "https://httpbin.org/get?name=germey&age=25"
}
这里可以看到,其实际请求的 URL 为 https://httpbin.org/get?name=germey&age=25,其 URL 请求参数就对应了 params 的内容。
其他请求类型
另外 aiohttp 还支持其他的请求类型,如 POST、PUT、DELETE 等等,这个和 requests 的使用方式有点类似,示例如下:
session.post('http://httpbin.org/post', data=b'data')
session.put('http://httpbin.org/put', data=b'data')
session.delete('http://httpbin.org/delete')
session.head('http://httpbin.org/get')
session.options('http://httpbin.org/get')
session.patch('http://httpbin.org/patch', data=b'data')
POST 数据
对于 POST 表单提交,其对应的请求头的 Content-type 为 application/x-www-form-urlencoded,我们可以用如下方式来实现,代码示例如下:
import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://httpbin.org/post', data=data) as response:
print(await response.text())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python/3.7 aiohttp/3.6.2",
"X-Amzn-Trace-Id": "Root=1-5e85f0b2-9017ea603a68dc285e0552d0"
},
"json": null,
"origin": "17.20.255.58",
"url": "https://httpbin.org/post"
}
对于 POST JSON 数据提交,其对应的请求头的 Content-type 为 application/json,我们只需要将 post 方法的 data 参数改成 json 即可,代码示例如下:
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://httpbin.org/post', json=data) as response:
print(await response.text())
运行结果如下:
{
"args": {},
"data": "{\"name\": \"germey\", \"age\": 25}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "29",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "Python/3.7 aiohttp/3.6.2",
"X-Amzn-Trace-Id": "Root=1-5e85f03e-c91c9a20c79b9780dbed7540"
},
"json": {
"age": 25,
"name": "germey"
},
"origin": "17.20.255.58",
"url": "https://httpbin.org/post"
}
响应字段
对于响应来说,我们可以用如下的方法分别获取响应的状态码、响应头、响应体、响应体二进制内容、响应体 JSON 结果,代码示例如下:
import aiohttp
import asyncio
async def main():
data = {'name': 'germey', 'age': 25}
async with aiohttp.ClientSession() as session:
async with session.post('https://httpbin.org/post', data=data) as response:
print('status:', response.status)
print('headers:', response.headers)
print('body:', await response.text())
print('bytes:', await response.read())
print('json:', await response.json())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果如下:
status: 200
headers: <CIMultiDictProxy('Date': 'Thu, 02 Apr 2020 14:13:05 GMT', 'Content-Type': 'application/json', 'Content-Length': '503', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true')>
body: {
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python/3.7 aiohttp/3.6.2",
"X-Amzn-Trace-Id": "Root=1-5e85f2f1-f55326ff5800b15886c8e029"
},
"json": null,
"origin": "17.20.255.58",
"url": "https://httpbin.org/post"
}
bytes: b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "age": "25", \n "name": "germey"\n }, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Content-Length": "18", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python/3.7 aiohttp/3.6.2", \n "X-Amzn-Trace-Id": "Root=1-5e85f2f1-f55326ff5800b15886c8e029"\n }, \n "json": null, \n "origin": "17.20.255.58", \n "url": "https://httpbin.org/post"\n}\n'
json: {'args': {}, 'data': '', 'files': {}, 'form': {'age': '25', 'name': 'germey'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '18', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'Python/3.7 aiohttp/3.6.2', 'X-Amzn-Trace-Id': 'Root=1-5e85f2f1-f55326ff5800b15886c8e029'}, 'json': None, 'origin': '17.20.255.58', 'url': 'https://httpbin.org/post'}
这里我们可以看到有些字段前面需要加 await,有的则不需要。其原则是,如果其返回的是一个 coroutine 对象(如 async 修饰的方法),那么前面就要加 await,具体可以看 aiohttp 的 API,其链接为:https://docs.aiohttp.org/en/stable/client_reference.html。
超时设置
对于超时的设置,我们可以借助于 ClientTimeout 对象,比如这里我要设置 1 秒的超时,可以这么来实现:
import aiohttp
import asyncio
async def main():
timeout = aiohttp.ClientTimeout(total=1)
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get('https://httpbin.org/get') as response:
print('status:', response.status)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
如果在 1 秒之内成功获取响应的话,运行结果如下:
200
如果超时的话,会抛出 TimeoutError 异常,其类型为 asyncio.TimeoutError,我们再进行异常捕获即可。
另外 ClientTimeout 对象声明时还有其他参数,如 connect、socket_connect 等,详细说明可以参考官方文档:https://docs.aiohttp.org/en/stable/client_quickstart.html#timeouts。
并发限制
由于 aiohttp 可以支持非常大的并发,比如上万、十万、百万都是能做到的,但这么大的并发量,目标网站是很可能在短时间内无法响应的,而且很可能瞬时间将目标网站爬挂掉。所以我们需要控制一下爬取的并发量。
在一般情况下,我们可以借助于 asyncio 的 Semaphore 来控制并发量,代码示例如下:
import asyncio
import aiohttp
CONCURRENCY = 5
URL = 'https://www.baidu.com'
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
async def scrape_api():
async with semaphore:
print('scraping', URL)
async with session.get(URL) as response:
await asyncio.sleep(1)
return await response.text()
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_api()) for _ in range(10000)]
await asyncio.gather(*scrape_index_tasks)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
在这里我们声明了 CONCURRENCY 代表爬取的最大并发量为 5,同时声明爬取的目标 URL 为百度。接着我们借助于 Semaphore 创建了一个信号量对象,赋值为 semaphore,这样我们就可以用它来控制最大并发量了。怎么使用呢?我们这里把它直接放置在对应的爬取方法里面,使用 async with 语句将 semaphore 作为上下文对象即可。这样的话,信号量可以控制进入爬取的最大协程数量,最大数量就是我们声明的 CONCURRENCY 的值。
在 main 方法里面,我们声明了 10000 个 task,传递给 gather 方法运行。倘若不加以限制,这 10000 个 task 会被同时执行,并发数量太大。但有了信号量的控制之后,同时运行的 task 的数量最大会被控制在 5 个,这样就能给 aiohttp 限制速度了。
在这里,aiohttp 的基本使用就介绍这么多,更详细的内容还是推荐你到官方文档查阅,链接:https://docs.aiohttp.org/。
爬取实战
上面我们介绍了 aiohttp 的基本用法之后,下面我们来根据一个实例实现异步爬虫的实战演练吧。
本次我们要爬取的网站是:https://dynamic5.scrape.center/,页面如图所示。
这是一个书籍网站,整个网站包含了数千本书籍信息,网站是 JavaScript 渲染的,数据可以通过 Ajax 接口获取到,并且接口没有设置任何反爬措施和加密参数,另外由于这个网站比之前的电影案例网站数据量大一些,所以更加适合做异步爬取。
本课时我们要完成的目标有:
-
使用 aiohttp 完成全站的书籍数据爬取。
-
将数据通过异步的方式保存到 MongoDB 中。
在本课时开始之前,请确保你已经做好了如下准备工作:
-
安装好了 Python(最低为 Python 3.6 版本,最好为 3.7 版本或以上),并能成功运行 Python 程序。
-
了解了 Ajax 爬取的一些基本原理和模拟方法。
-
了解了异步爬虫的基本原理和 asyncio 库的基本用法。
-
了解了 aiohttp 库的基本用法。
-
安装并成功运行了 MongoDB 数据库,并安装了异步存储库 motor。
注:这里要实现 MongoDB 异步存储,需要异步 MongoDB 存储库,叫作 motor,安装命令为:
pip3 install motor
页面分析
在之前我们讲解了 Ajax 的基本分析方法,本课时的站点结构和之前 Ajax 分析的站点结构类似,都是列表页加详情页的结构,加载方式都是 Ajax,所以我们能轻松分析到如下信息:
-
列表页的 Ajax 请求接口格式为:https://dynamic5.scrape.center/api/book/?limit=18&offset={offset},limit 的值即为每一页的书的个数,offset 的值为每一页的偏移量,其计算公式为 offset = limit * (page - 1) ,如第 1 页 offset 的值为 0,第 2 页 offset 的值为 18,以此类推。
-
列表页 Ajax 接口返回的数据里 results 字段包含当前页 18 本书的信息,其中每本书的数据里面包含一个字段 id,这个 id 就是书本身的 ID,可以用来进一步请求详情页。
-
详情页的 Ajax 请求接口格式为:https://dynamic5.scrape.center/api/book/{id},id 即为书的 ID,可以从列表页的返回结果中获取。
如果你掌握了 Ajax 爬取实战一课时的内容话,上面的内容应该很容易分析出来。如有难度,可以复习下之前的知识。
实现思路
其实一个完善的异步爬虫应该能够充分利用资源进行全速爬取,其思路是维护一个动态变化的爬取队列,每产生一个新的 task 就会将其放入队列中,有专门的爬虫消费者从队列中获取 task 并执行,能做到在最大并发量的前提下充分利用等待时间进行额外的爬取处理。
但上面的实现思路整体较为烦琐,需要设计爬取队列、回调函数、消费者等机制,需要实现的功能较多。由于我们刚刚接触 aiohttp 的基本用法,本课时也主要是了解 aiohttp 的实战应用,所以这里我们将爬取案例的实现稍微简化一下。
在这里我们将爬取的逻辑拆分成两部分,第一部分为爬取列表页,第二部分为爬取详情页。由于异步爬虫的关键点在于并发执行,所以我们可以将爬取拆分为两个阶段:
-
第一阶段为所有列表页的异步爬取,我们可以将所有的列表页的爬取任务集合起来,声明为 task 组成的列表,进行异步爬取。
-
第二阶段则是拿到上一步列表页的所有内容并解析,拿到所有书的 id 信息,组合为所有详情页的爬取任务集合,声明为 task 组成的列表,进行异步爬取,同时爬取的结果也以异步的方式存储到 MongoDB 里面。
因为两个阶段的拆分之后需要串行执行,所以可能不能达到协程的最佳调度方式和资源利用情况,但也差不了很多。但这个实现思路比较简单清晰,代码实现也比较简单,能够帮我们快速了解 aiohttp 的基本使用。
基本配置
首先我们先配置一些基本的变量并引入一些必需的库,代码如下:
import asyncio
import aiohttp
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://dynamic5.scrape.center/api/book/?limit=18&offset={offset}'
DETAIL_URL = 'https://dynamic5.scrape.center/api/book/{id}'
PAGE_SIZE = 18
PAGE_NUMBER = 100
CONCURRENCY = 5
在这里我们导入了 asyncio、aiohttp、logging 这三个库,然后定义了 logging 的基本配置。接着定义了 URL、爬取页码数量 PAGE_NUMBER、并发量 CONCURRENCY 等信息。
爬取列表页
首先,第一阶段我们就来爬取列表页,还是和之前一样,我们先定义一个通用的爬取方法,代码如下:
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s', url)
async with session.get(url) as response:
return await response.json()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s', url, exc_info=True)
在这里我们声明了一个信号量,用来控制最大并发数量。
接着我们定义了 scrape_api 方法,该方法接收一个参数 url。首先使用 async with 引入信号量作为上下文,接着调用了 session 的 get 方法请求这个 url,然后返回响应的 JSON 格式的结果。另外这里还进行了异常处理,捕获了 ClientError,如果出现错误,会输出异常信息。
接着,对于列表页的爬取,实现如下:
async def scrape_index(page):
url = INDEX_URL.format(offset=PAGE_SIZE * (page - 1))
return await scrape_api(url)
这里定义了一个 scrape_index 方法用于爬取列表页,它接收一个参数为 page,然后构造了列表页的 URL,将其传给 scrape_api 方法即可。这里注意方法同样需要用 async 修饰,调用的 scrape_api 方法前面需要加 await,因为 scrape_api 调用之后本身会返回一个 coroutine。另外由于 scrape_api 返回结果就是 JSON 格式,因此 scrape_index 的返回结果就是我们想要爬取的信息,不需要再额外解析了。
好,接着我们定义一个 main 方法,将上面的方法串联起来调用一下,实现如下:
import json
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(scrape_index(page)) for page in range(1, PAGE_NUMBER + 1)]
results = await asyncio.gather(*scrape_index_tasks)
logging.info('results %s', json.dumps(results, ensure_ascii=False, indent=2))
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
这里我们首先声明了 session 对象,即最初声明的全局变量,将 session 作为全局变量的话我们就不需要每次在各个方法里面传递了,实现比较简单。
接着我们定义了 scrape_index_tasks,它就是爬取列表页的所有 task,接着我们调用 asyncio 的 gather 方法并传入 task 列表,将结果赋值为 results,它是所有 task 返回结果组成的列表。
最后我们调用 main 方法,使用事件循环启动该 main 方法对应的协程即可。
运行结果如下:
2020-04-03 03:45:54,692 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=0
2020-04-03 03:45:54,707 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=18
2020-04-03 03:45:54,707 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=36
2020-04-03 03:45:54,708 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=54
2020-04-03 03:45:54,708 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=72
2020-04-03 03:45:56,431 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=90
2020-04-03 03:45:56,435 - INFO: scraping https://dynamic5.scrape.center/api/book/?limit=18&offset=108
可以看到这里就开始异步爬取了,并发量是由我们控制的,目前为 5,当然也可以进一步调高并发量,在网站能承受的情况下,爬取速度会进一步加快。
最后 results 就是所有列表页得到的结果,我们将其赋值为 results 对象,接着我们就可以用它来进行第二阶段的爬取了。
爬取详情页
第二阶段就是爬取详情页并保存数据了,由于每个详情页对应一本书,每本书需要一个 ID,而这个 ID 又正好存在 results 里面,所以下面我们就需要将所有详情页的 ID 获取出来。
在 main 方法里增加 results 的解析代码,实现如下:
ids = []
for index_data in results:
if not index_data: continue
for item in index_data.get('results'):
ids.append(item.get('id'))
这样 ids 就是所有书的 id 了,然后我们用所有的 id 来构造所有详情页对应的 task,来进行异步爬取即可。
那么这里再定义一个爬取详情页和保存数据的方法,实现如下:
from motor.motor_asyncio import AsyncIOMotorClient
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'books'
MONGO_COLLECTION_NAME = 'books'
client = AsyncIOMotorClient(MONGO_CONNECTION_STRING)
db = client[MONGO_DB_NAME]
collection = db[MONGO_COLLECTION_NAME]
async def save_data(data):
logging.info('saving data %s', data)
if data:
return await collection.update_one({
'id': data.get('id')
}, {
'$set': data
}, upsert=True)
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
await save_data(data)
这里我们定义了 scrape_detail 方法用于爬取详情页数据并调用 save_data 方法保存数据,save_data 方法用于将数据库保存到 MongoDB 里面。
在这里我们用到了支持异步的 MongoDB 存储库 motor,MongoDB 的连接声明和 pymongo 是类似的,保存数据的调用方法也是基本一致,不过整个都换成了异步方法。
好,接着我们就在 main 方法里面增加 scrape_detail 方法的调用即可,实现如下:
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]
await asyncio.wait(scrape_detail_tasks)
await session.close()
在这里我们先声明了 scrape_detail_tasks,即所有详情页的爬取 task 组成的列表,接着调用了 asyncio 的 wait 方法调用执行即可,当然这里也可以用 gather 方法,效果是一样的,只不过返回结果略有差异。最后全部执行完毕关闭 session 即可。
一些详情页的爬取过程运行如下:
2020-04-03 04:00:32,576 - INFO: scraping https://dynamic5.scrape.center/api/book/2301475
2020-04-03 04:00:32,576 - INFO: scraping https://dynamic5.scrape.center/api/book/2351866
2020-04-03 04:00:32,577 - INFO: scraping https://dynamic5.scrape.center/api/book/2828384
2020-04-03 04:00:32,577 - INFO: scraping https://dynamic5.scrape.center/api/book/3040352
2020-04-03 04:00:32,578 - INFO: scraping https://dynamic5.scrape.center/api/book/3074810
2020-04-03 04:00:44,858 - INFO: saving data {'id': '3040352', 'comments': [{'id': '387952888', 'content': '温馨文,青梅竹马神马的很有爱~'}, ..., {'id': '2005314253', 'content': '沈晋&秦央,文比较短,平平淡淡,贴近生活,短文的缺点不细腻'}], 'name': '那些风花雪月', 'authors': ['\n 公子欢喜'], 'translators': [], 'publisher': '龍馬出版社', 'tags': ['公子欢喜', '耽美', 'BL', '小说', '现代', '校园', '耽美小说', '那些风花雪月'], 'url': 'https://book.douban.com/subject/3040352/', 'isbn': '9789866685156', 'cover': 'https://img9.doubanio.com/view/subject/l/public/s3029724.jpg', 'page_number': None, 'price': None, 'score': '8.1', 'introduction': '', 'catalog': None, 'published_at': '2008-03-26T16:00:00Z', 'updated_at': '2020-03-21T16:59:39.584722Z'}
2020-04-03 04:00:44,859 - INFO: scraping https://dynamic5.scrape.center/api/book/2994915
...
最后我们观察下,爬取到的数据也都保存到 MongoDB 数据库里面了,如图所示:
至此,我们就使用 aiohttp 完成了书籍网站的异步爬取。
总结
本课时的内容较多,我们了解了 aiohttp 的基本用法,然后通过一个实例讲解了 aiohttp 异步爬虫的具体实现。学习过程我们可以发现,相比普通的单线程爬虫来说,使用异步可以大大提高爬取效率,后面我们也可以多多使用。
本课时代码:https://github.com/Germey/ScrapeDynamic5。
爬虫神器Pyppeteer的使用
在前面我们学习了 Selenium 的基本用法,它功能的确非常强大,但很多时候我们会发现 Selenium 有一些不太方便的地方,比如环境的配置,得安装好相关浏览器,比如 Chrome、Firefox 等等,然后还要到官方网站去下载对应的驱动,最重要的还需要安装对应的 Python Selenium 库,而且版本也得好好看看是否对应,确实不是很方便,另外如果要做大规模部署的话,环境配置的一些问题也是个头疼的事情。
那么本课时我们就介绍另一个类似的替代品,叫作 Pyppeteer。注意,是叫作 Pyppeteer,而不是 Puppeteer。
Pyppeteer 介绍
Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大,Selenium 当然同样可以做到。
而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但它不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。
Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。两款浏览器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。

总的来说,两款浏览器的内核是一样的,实现方式也是一样的,可以认为是开发版和正式版的区别,功能上基本是没有太大区别的。
Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。那么有了 Pyppeteer 之后,我们就可以免去那些烦琐的环境配置等问题。如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了烦琐的环境配置等工作。另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
那么下面就让我们来一起了解下 Pyppeteer 的相关用法吧。
安装
首先就是安装问题了,由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上。
安装方式非常简单:
pip3 install pyppeteer
好了,安装完成之后我们在命令行下测试:
>>> import pyppeteer
如果没有报错,那么就证明安装成功了。
快速上手
接下来我们测试基本的页面渲染操作,这里我们选用的网址为:https://dynamic2.scrape.center/,如图所示。
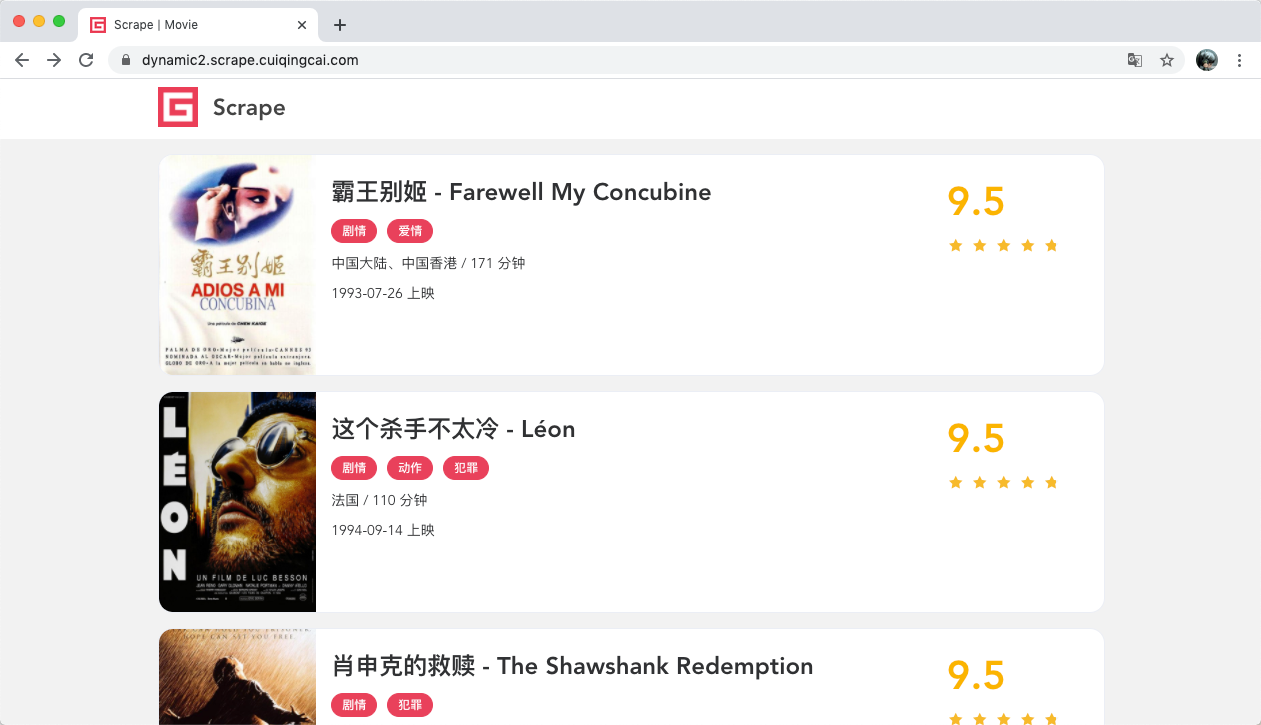
这个网站我们在之前的 Selenium 爬取实战课时中已经分析过了,整个页面是用 JavaScript 渲染出来的,同时一些 Ajax 接口还带有加密参数,所以这个网站的页面我们无法直接使用 requests 来抓取看到的数据,同时我们也不太好直接模拟 Ajax 来获取数据。
所以前面一课时我们介绍了使用 Selenium 爬取的方式,其原理就是模拟浏览器的操作,直接用浏览器把页面渲染出来,然后再直接获取渲染后的结果。同样的原理,用 Pyppeteer 也可以做到。
下面我们用 Pyppeteer 来试试,代码就可以写为如下形式:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.center/')
await page.waitForSelector('.item .name')
doc = pq(await page.content())
names = [item.text() for item in doc('.item .name').items()]
print('Names:', names)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
运行结果:
Names: ['霸王别姬 - Farewell My Concubine', '这个杀手不太冷 - Léon', '肖申克的救赎 - The Shawshank Redemption', '泰坦尼克号 - Titanic', '罗马假日 - Roman Holiday', '唐伯虎点秋香 - Flirting Scholar', '乱世佳人 - Gone with the Wind', '喜剧之王 - The King of Comedy', '楚门的世界 - The Truman Show', '狮子王 - The Lion King']
先初步看下代码,大体意思是访问了这个网站,然后等待 .item .name 的节点加载出来,随后通过 pyquery 从网页源码中提取了电影的名称并输出,最后关闭 Pyppeteer。
看运行结果,和之前的 Selenium 一样,我们成功模拟加载出来了页面,然后提取到了首页所有电影的名称。
那么这里面的具体过程发生了什么?我们来逐行看下。
-
launch 方法会新建一个 Browser 对象,其执行后最终会得到一个 Browser 对象,然后赋值给 browser。这一步就相当于启动了浏览器。
-
然后 browser 调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象,这时候新启动了一个选项卡,但是还未访问任何页面,浏览器依然是空白。
-
随后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载。
-
Page 对象调用 waitForSelector 方法,传入选择器,那么页面就会等待选择器所对应的节点信息加载出来,如果加载出来了,立即返回,否则会持续等待直到超时。此时如果顺利的话,页面会成功加载出来。
-
页面加载完成之后再调用 content 方法,可以获得当前浏览器页面的源代码,这就是 JavaScript 渲染后的结果。
-
然后进一步的,我们用 pyquery 进行解析并提取页面的电影名称,就得到最终结果了。
另外其他的一些方法如调用 asyncio 的 get_event_loop 等方法的相关操作则属于 Python 异步 async 相关的内容了,你如果不熟悉可以了解下前面所讲的异步相关知识。
好,通过上面的代码,我们同样也可以完成 JavaScript 渲染页面的爬取了。怎么样?代码相比 Selenium 是不是更简洁易读,而且环境配置更加方便。在这个过程中,我们没有配置 Chrome 浏览器,也没有配置浏览器驱动,免去了一些烦琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取。
接下来我们再看看另外一个例子,这个例子设定了浏览器窗口大小,然后模拟了网页截图,另外还可以执行自定义的 JavaScript 获得特定的内容,代码如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.center/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们又用到了几个新的 API,完成了页面窗口大小设置、网页截图保存、执行 JavaScript 并返回对应数据。
首先 screenshot 方法可以传入保存的图片路径,另外还可以指定保存格式 type、清晰度 quality、是否全屏 fullPage、裁切 clip 等各个参数实现截图。
截图的样例如下:
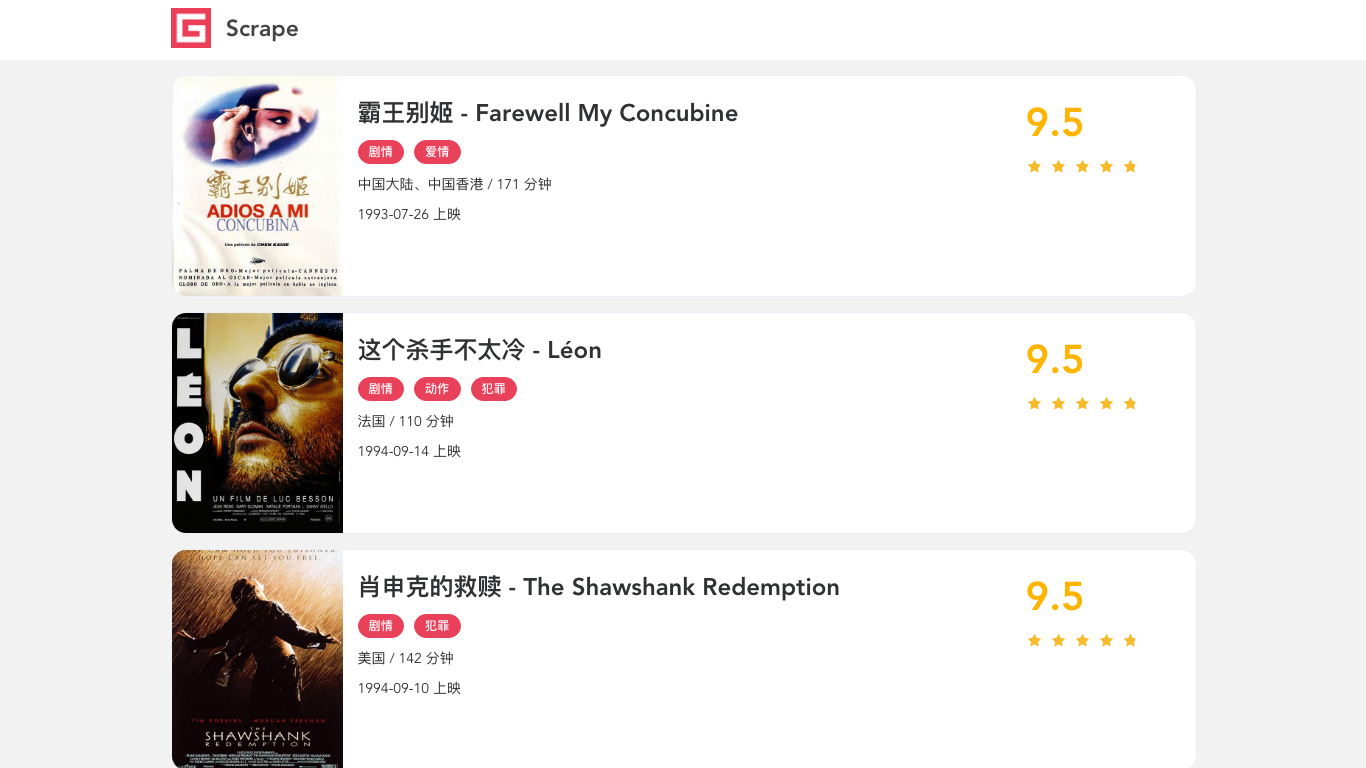
可以看到它返回的就是 JavaScript 渲染后的页面,和我们在浏览器中看到的结果是一模一样的。
最后我们又调用了 evaluate 方法执行了一些 JavaScript,JavaScript 传入的是一个函数,使用 return 方法返回了网页的宽高、像素大小比率三个值,最后得到的是一个 JSON 格式的对象,内容如下:
{'width': 1366, 'height': 768, 'deviceScaleFactor': 1}
OK,实例就先感受到这里,还有太多太多的功能还没提及。
总之利用 Pyppeteer 我们可以控制浏览器执行几乎所有动作,想要的操作和功能基本都可以实现,用它来自由地控制爬虫当然就不在话下了。
详细用法
了解了基本的实例之后,我们再来梳理一下 Pyppeteer 的一些基本和常用操作。Pyppeteer 的几乎所有功能都能在其官方文档的 API Reference 里面找到,链接为:https://miyakogi.github.io/pyppeteer/reference.html,用到哪个方法就来这里查询就好了,参数不必死记硬背,即用即查就好。
launch
使用 Pyppeteer 的第一步便是启动浏览器,首先我们看下怎样启动一个浏览器,其实就相当于我们点击桌面上的浏览器图标一样,把它运行起来。用 Pyppeteer 完成同样的操作,只需要调用 launch 方法即可。
我们先看下 launch 方法的 API,链接为:https://miyakogi.github.io/pyppeteer/reference.html#pyppeteer.launcher.launch,其方法定义如下:
pyppeteer.launcher.launch(options: dict = None, **kwargs) → pyppeteer.browser.Browser
可以看到它处于 launcher 模块中,参数没有在声明中特别指定,返回类型是 browser 模块中的 Browser 对象,另外观察源码发现这是一个 async 修饰的方法,所以调用它的时候需要使用 await。
接下来看看它的参数:
-
ignoreHTTPSErrors (bool):是否要忽略 HTTPS 的错误,默认是 False。
-
headless (bool):是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
-
executablePath (str):可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
-
slowMo (int|float):通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。
-
args (List[str]):在执行过程中可以传入的额外参数。
-
ignoreDefaultArgs (bool):不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。
-
handleSIGINT (bool):是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认是 True。
-
handleSIGTERM (bool):是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。
-
handleSIGHUP (bool):是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。
-
dumpio (bool):是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默认是 False。
-
userDataDir (str):即用户数据文件夹,即可以保留一些个性化配置和操作记录。
-
env (dict):环境变量,可以通过字典形式传入。
-
devtools (bool):是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
-
logLevel (int|str):日志级别,默认和 root logger 对象的级别相同。
-
autoClose (bool):当一些命令执行完之后,是否自动关闭浏览器,默认是 True。
-
loop (asyncio.AbstractEventLoop):事件循环对象。
好了,知道这些参数之后,我们可以先试试看。
-
无头模式
首先可以试用下最常用的参数 headless,如果我们将它设置为 True 或者默认不设置它,在启动的时候我们是看不到任何界面的,如果把它设置为 False,那么在启动的时候就可以看到界面了,一般我们在调试的时候会把它设置为 False,在生产环境上就可以设置为 True,我们先尝试一下关闭 headless 模式:
import asyncio
from pyppeteer import launch
async def main():
await launch(headless=False)
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
运行之后看不到任何控制台输出,但是这时候就会出现一个空白的 Chromium 界面了:
但是可以看到这就是一个光秃秃的浏览器而已,看一下相关信息:
看到了,这就是 Chromium,上面还写了开发者内部版本,你可以认为是开发版的 Chrome 浏览器就好。
-
调试模式
另外我们还可以开启调试模式,比如在写爬虫的时候会经常需要分析网页结构还有网络请求,所以开启调试工具还是很有必要的,我们可以将 devtools 参数设置为 True,这样每开启一个界面就会弹出一个调试窗口,非常方便,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(devtools=True)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
刚才说过 devtools 这个参数如果设置为了 True,那么 headless 就会被关闭了,界面始终会显现出来。在这里我们新建了一个页面,打开了百度,界面运行效果如下:
-
禁用提示条
这时候我们可以看到上面的一条提示:"Chrome 正受到自动测试软件的控制",这个提示条有点烦,那该怎样关闭呢?这时候就需要用到 args 参数了,禁用操作如下:
browser = await launch(headless=False, args=['--disable-infobars'])
这里就不再写完整代码了,就是在 launch 方法中,args 参数通过 list 形式传入即可,这里使用的是 --disable-infobars 的参数。
-
防止检测
你可能会说,如果你只是把提示关闭了,有些网站还是会检测到是 WebDriver 吧,比如拿之前的检测 WebDriver 的案例 https://antispider1.scrape.center/ 来验证下,我们可以试试:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://antispider1.scrape.center/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
果然还是被检测到了,页面如下:
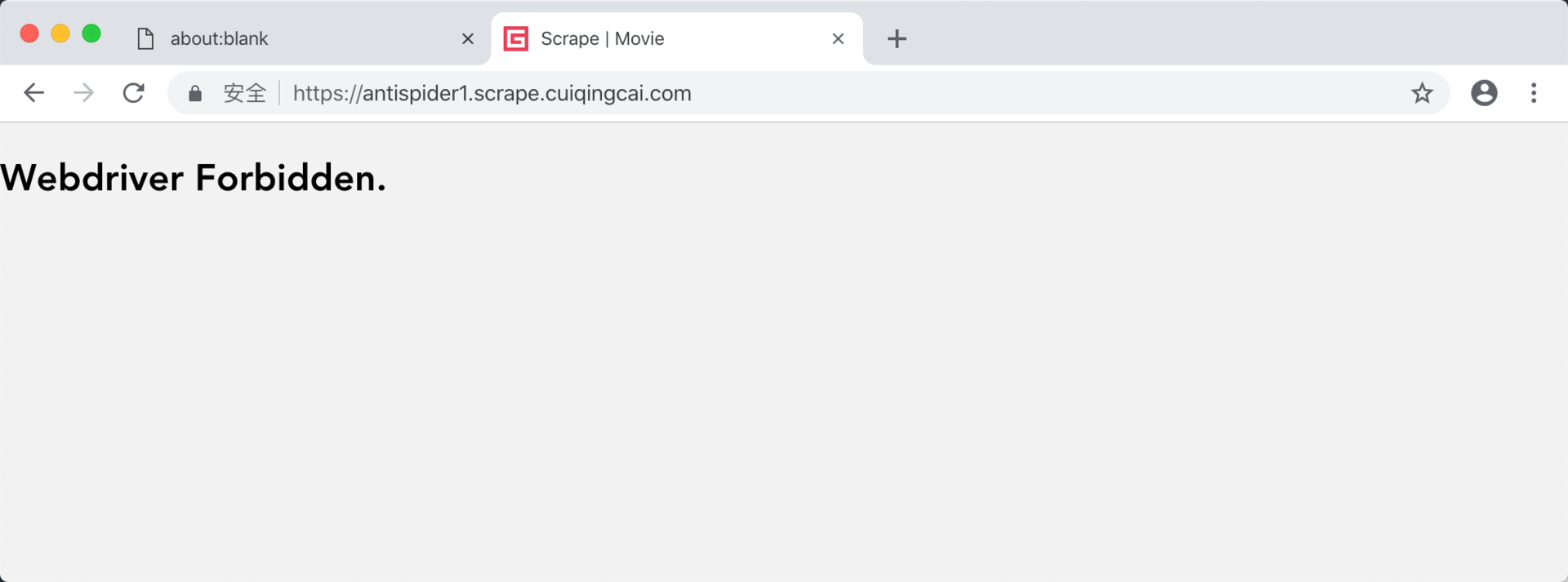
这说明 Pyppeteer 开启 Chromium 照样还是能被检测到 WebDriver 的存在。
那么此时如何规避呢?Pyppeteer 的 Page 对象有一个方法叫作 evaluateOnNewDocument,意思就是在每次加载网页的时候执行某个语句,所以这里我们可以执行一下将 WebDriver 隐藏的命令,改写如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.center/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
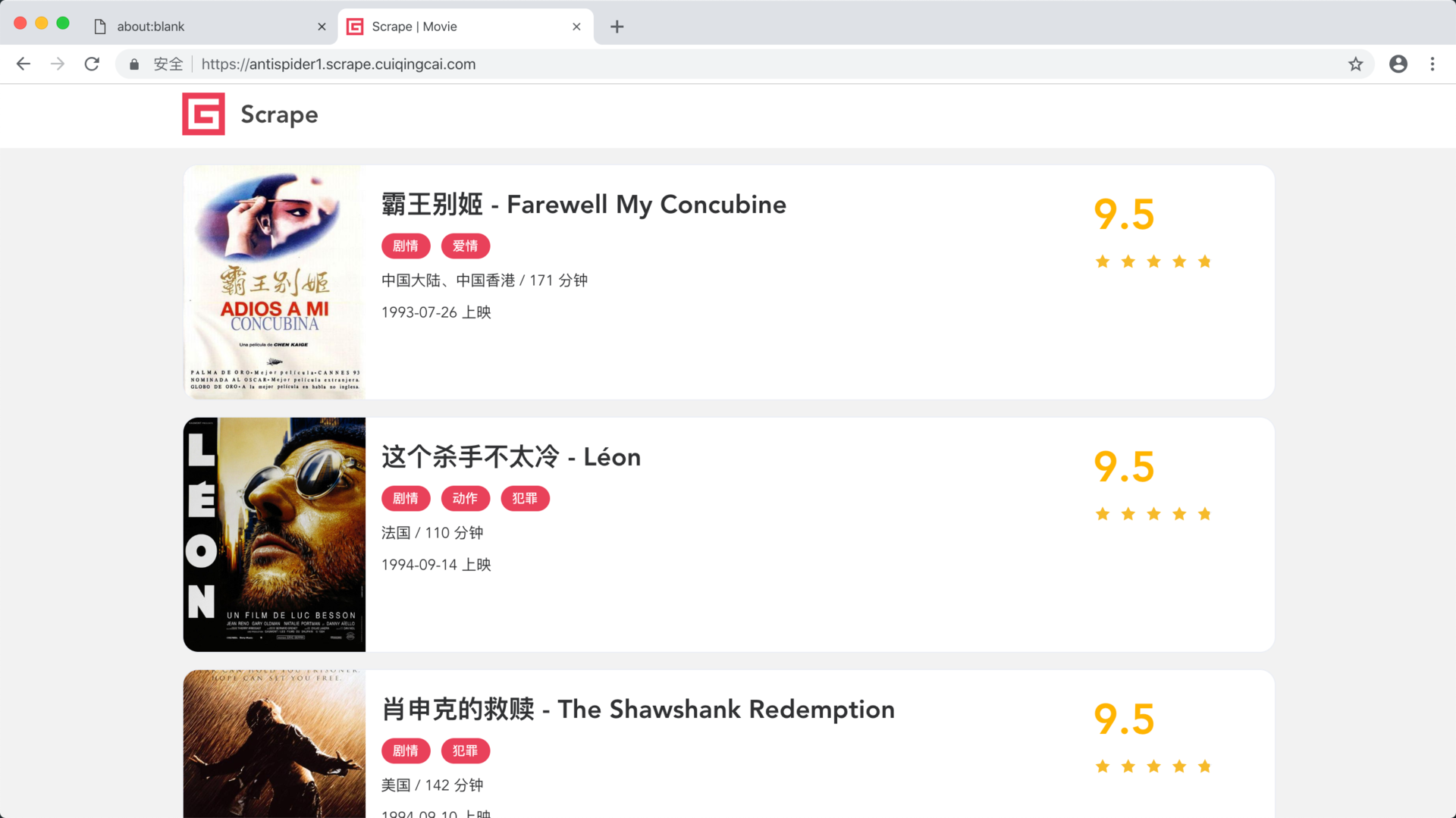
这里我们可以看到整个页面就可以成功加载出来了,如图所示。

我们发现页面就成功加载出来了,绕过了 WebDriver 的检测。
-
页面大小设置
在上面的例子中,我们还发现了页面的显示 bug,整个浏览器窗口比显示的内容窗口要大,这个是某些页面会出现的情况。
对于这种情况,我们通过设置窗口大小就可以解决,可以通过 Page 的 setViewport 方法设置,代码如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.center/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里我们同时设置了浏览器窗口的宽高以及显示区域的宽高,使得二者一致,最后发现显示就正常了,如图所示。
-
用户数据持久化
刚才我们可以看到,每次我们打开 Pyppeteer 的时候都是一个新的空白的浏览器。而且如果遇到了需要登录的网页之后,如果我们这次登录上了,下一次再启动又是空白了,又得登录一次,这的确是一个问题。
比如以淘宝举例,平时我们逛淘宝的时候,在很多情况下关闭了浏览器再打开,淘宝依然还是登录状态。这是因为淘宝的一些关键 Cookies 已经保存到本地了,下次登录的时候可以直接读取并保持登录状态。
那么这些信息保存在哪里了呢?其实就是保存在用户目录下了,里面不仅包含了浏览器的基本配置信息,还有一些 Cache、Cookies 等各种信息都在里面,如果我们能在浏览器启动的时候读取这些信息,那么启动的时候就可以恢复一些历史记录甚至一些登录状态信息了。
这也就解决了一个问题:很多时候你在每次启动 Selenium 或 Pyppeteer 的时候总是一个全新的浏览器,那这究其原因就是没有设置用户目录,如果设置了它,每次打开就不再是一个全新的浏览器了,它可以恢复之前的历史记录,也可以恢复很多网站的登录信息。
那么这个怎么来做呢?很简单,在启动的时候设置 userDataDir 就好了,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='./userdata', args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
好,这里就是加了一个 userDataDir 的属性,值为 userdata,即当前目录的 userdata 文件夹。我们可以首先运行一下,然后登录一次淘宝,这时候我们同时可以观察到在当前运行目录下又多了一个 userdata 的文件夹,里面的结构是这样子的:

具体的介绍可以看官方的一些说明,如: https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md,这里面介绍了 userdatadir 的相关内容。
再次运行上面的代码,这时候可以发现现在就已经是登录状态了,不需要再次登录了,这样就成功跳过了登录的流程。当然可能时间太久了,Cookies 都过期了,那还是需要登录的。
以上便是 launch 方法及其对应的参数的配置。
Browser
上面我们了解了 launch 方法,其返回的就是一个 Browser 对象,即浏览器对象,我们会通常将其赋值给 browser 变量,其实它就是 Browser 类的一个实例。
下面我们来看看 Browser 类的定义:
class pyppeteer.browser.Browser(connection: pyppeteer.connection.Connection, contextIds: List[str], ignoreHTTPSErrors: bool, setDefaultViewport: bool, process: Optional[subprocess.Popen] = None, closeCallback: Callable[[], Awaitable[None]] = None, **kwargs)
这里我们可以看到其构造方法有很多参数,但其实多数情况下我们直接使用 launch 方法或 connect 方法创建即可。
browser 作为一个对象,其自然有很多用于操作浏览器本身的方法,下面我们来选取一些比较有用的介绍下。
-
开启无痕模式
我们知道 Chrome 浏览器是有一个无痕模式的,它的好处就是环境比较干净,不与其他的浏览器示例共享 Cache、Cookies 等内容,其开启方式可以通过 createIncognitoBrowserContext 方法,示例如下:
import asyncio
from pyppeteer import launch
width, height = 1200, 768
async def main():
browser = await launch(headless=False,
args=['--disable-infobars', f'--window-size={width},{height}'])
context = await browser.createIncognitoBrowserContext()
page = await context.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里关键的调用就是 createIncognitoBrowserContext 方法,其返回一个 context 对象,然后利用 context 对象我们可以新建选项卡。
运行之后,我们发现浏览器就进入了无痕模式,界面如下:
-
关闭
怎样关闭自不用多说了,就是 close 方法,但很多时候我们可能忘记了关闭而造成额外开销,所以要记得在使用完毕之后调用一下 close 方法,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.center/')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Page
Page 即页面,就对应一个网页,一个选项卡。在前面我们已经演示了几个 Page 方法的操作了,这里我们再详细看下它的一些常用用法。
-
选择器
Page 对象内置了一些用于选取节点的选择器方法,如 J 方法传入一个选择器 Selector,则能返回对应匹配的第一个节点,等价于 querySelector。如 JJ 方法则是返回符合 Selector 的列表,类似于 querySelectorAll。
下面我们来看下其用法和运行结果,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.center/')
await page.waitForSelector('.item .name')
j_result1 = await page.J('.item .name')
j_result2 = await page.querySelector('.item .name')
jj_result1 = await page.JJ('.item .name')
jj_result2 = await page.querySelectorAll('.item .name')
print('J Result1:', j_result1)
print('J Result2:', j_result2)
print('JJ Result1:', jj_result1)
print('JJ Result2:', jj_result2)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
在这里我们分别调用了 J、querySelector、JJ、querySelectorAll 四个方法,观察下其运行效果和返回结果的类型,运行结果:
J Result1: <pyppeteer.element_handle.ElementHandle object at 0x1166f7dd0>
J Result2: <pyppeteer.element_handle.ElementHandle object at 0x1166f07d0>
JJ Result1: [<pyppeteer.element_handle.ElementHandle object at 0x11677df50>, <pyppeteer.element_handle.ElementHandle object at 0x1167857d0>, <pyppeteer.element_handle.ElementHandle object at 0x116785110>,
...
<pyppeteer.element_handle.ElementHandle object at 0x11679db10>, <pyppeteer.element_handle.ElementHandle object at 0x11679dbd0>]
JJ Result2: [<pyppeteer.element_handle.ElementHandle object at 0x116794f10>, <pyppeteer.element_handle.ElementHandle object at 0x116794d10>, <pyppeteer.element_handle.ElementHandle object at 0x116794f50>,
...
<pyppeteer.element_handle.ElementHandle object at 0x11679f690>, <pyppeteer.element_handle.ElementHandle object at 0x11679f750>]
在这里我们可以看到,J、querySelector 一样,返回了单个匹配到的节点,返回类型为 ElementHandle 对象。JJ、querySelectorAll 则返回了节点列表,是 ElementHandle 的列表。
-
选项卡操作
前面我们已经演示了多次新建选项卡的操作了,也就是 newPage 方法,那新建了之后怎样获取和切换呢,下面我们来看一个例子:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
page = await browser.newPage()
await page.goto('https://www.bing.com')
pages = await browser.pages()
print('Pages:', pages)
page1 = pages[1]
await page1.bringToFront()
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
在这里我们启动了 Pyppeteer,然后调用了 newPage 方法新建了两个选项卡并访问了两个网站。那么如果我们要切换选项卡的话,只需要调用 pages 方法即可获取所有的页面,然后选一个页面调用其 bringToFront 方法即可切换到该页面对应的选项卡。
-
常见操作
作为一个页面,我们一定要有对应的方法来控制,如加载、前进、后退、关闭、保存等,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic1.scrape.center/')
await page.goto('https://dynamic2.scrape.center/')
# 后退
await page.goBack()
# 前进
await page.goForward()
# 刷新
await page.reload()
# 保存 PDF
await page.pdf()
# 截图
await page.screenshot()
# 设置页面 HTML
await page.setContent('<h2>Hello World</h2>')
# 设置 User-Agent
await page.setUserAgent('Python')
# 设置 Headers
await page.setExtraHTTPHeaders(headers={})
# 关闭
await page.close()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们介绍了一些常用方法,除了一些常用的操作,这里还介绍了设置 User-Agent、Headers 等功能。
-
点击
Pyppeteer 同样可以模拟点击,调用其 click 方法即可。比如我们这里以 https://dynamic2.scrape.center/ 为例,等待节点加载出来之后,模拟右键点击一下,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.center/')
await page.waitForSelector('.item .name')
await page.click('.item .name', options={
'button': 'right',
'clickCount': 1, # 1 or 2
'delay': 3000, # 毫秒
})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里 click 方法第一个参数就是选择器,即在哪里操作。第二个参数是几项配置:
-
button:鼠标按钮,分为 left、middle、right。
-
clickCount:点击次数,如双击、单击等。
-
delay:延迟点击。
-
输入文本。
对于文本的输入,Pyppeteer 也不在话下,使用 type 方法即可,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.taobao.com')
# 后退
await page.type('#q', 'iPad')
# 关闭
await asyncio.sleep(10)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们打开淘宝网,使用 type 方法第一个参数传入选择器,第二个参数传入输入的内容,Pyppeteer 便可以帮我们完成输入了。
-
获取信息
Page 获取源代码用 content 方法即可,Cookies 则可以用 cookies 方法获取,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.center/')
print('HTML:', await page.content())
print('Cookies:', await page.cookies())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
-
执行
Pyppeteer 可以支持 JavaScript 执行,使用 evaluate 方法即可,看之前的例子:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.center/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里我们通过 evaluate 方法执行了 JavaScript,并获取到了对应的结果。另外其还有 exposeFunction、evaluateOnNewDocument、evaluateHandle 方法可以做了解。
-
延时等待
在本课时最开头的地方我们演示了 waitForSelector 的用法,它可以让页面等待某些符合条件的节点加载出来再返回。
在这里 waitForSelector 就是传入一个 CSS 选择器,如果找到了,立马返回结果,否则等待直到超时。
除了 waitForSelector 方法,还有很多其他的等待方法,介绍如下。
-
waitForFunction:等待某个 JavaScript 方法执行完毕或返回结果。
-
waitForNavigation:等待页面跳转,如果没加载出来就会报错。
-
waitForRequest:等待某个特定的请求被发出。
-
waitForResponse:等待某个特定的请求收到了回应。
-
waitFor:通用的等待方法。
-
waitForSelector:等待符合选择器的节点加载出来。
-
waitForXPath:等待符合 XPath 的节点加载出来。
通过等待条件,我们就可以控制页面加载的情况了。
更多
另外 Pyppeteer 还有很多功能,如键盘事件、鼠标事件、对话框事件等等,在这里就不再一一赘述了。更多的内容可以参考官方文档的案例说明:https://miyakogi.github.io/pyppeteer/reference.html。
以上,我们就通过一些小的案例介绍了 Pyppeteer 的基本用法,下一课时,我们来使用 Pyppeteer 完成一个实战案例爬取。
本节代码:https://github.com/Python3WebSpider/PyppeteerTest。
Pyppeteer爬取实战
在上一课时我们了解了 Pyppeteer 的基本用法,确实我们可以发现其相比 Selenium 有很多方便之处。
本课时我们就来使用 Pyppeteer 针对之前的 Selenium 案例做一次改写,来体会一下二者的不同之处,同时也加强一下对 Pyppeteer 的理解和掌握情况。
爬取目标
本课时我们要爬取的目标和之前是一样的,还是 Selenium 的那个案例,地址为:https://dynamic2.scrape.center/,如下图所示。
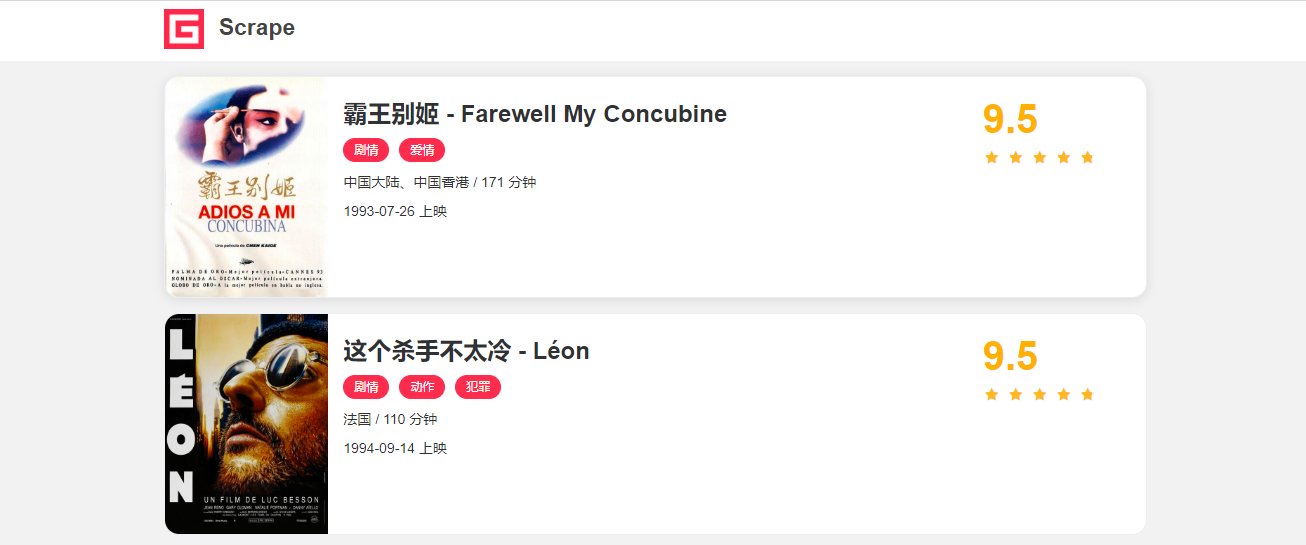
这个网站的每个详情页的 URL 都是带有加密参数的,同时 Ajax 接口也都有加密参数和时效性。具体的介绍可以看下 Selenium 课时。
本节目标
爬取目标和那一节也是一样的:
-
遍历每一页列表页,然后获取每部电影详情页的 URL。
-
爬取每部电影的详情页,然后提取其名称、评分、类别、封面、简介等信息。
-
爬取到的数据存为 JSON 文件。
要求和之前也是一样的,只不过我们这里的实现就全用 Pyppeteer 来做了。
准备工作
在本课时开始之前,我们需要做好如下准备工作:
-
安装好 Python (最低为 Python 3.6)版本,并能成功运行 Python 程序。
-
安装好 Pyppeteer 并能成功运行示例。
其他的浏览器、驱动配置就不需要了,这也是相比 Selenium 更加方便的地方。
页面分析在这里就不多介绍了,还是列表页 + 详情页的结构,具体可以参考 Selenium 那一课时的内容。
爬取列表页
首先我们先做一些准备工作,定义一些基础的配置,包括日志定义、变量等等并引入一些必要的包,代码如下:
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://dynamic2.scrape.center/page/{page}'
TIMEOUT = 10
TOTAL_PAGE = 10
WINDOW_WIDTH, WINDOW_HEIGHT = 1366, 768
HEADLESS = False
这里大多数的配置和之前是一样的,不过这里我们额外定义了窗口的宽高信息,这里定义为 1366 x 768,你也可以随意指定适合自己屏幕的宽高信息。另外这里定义了一个变量 HEADLESS,用来指定是否启用 Pyppeteer 的无头模式,如果为 False,那么启动 Pyppeteer 的时候就会弹出一个 Chromium 浏览器窗口。
接着我们再定义一个初始化 Pyppeteer 的方法,包括启动 Pyppeteer,新建一个页面选项卡,设置窗口大小等操作,代码实现如下:
from pyppeteer import launch
browser, tab = None, None
async def init():
global browser, tab
browser = await launch(headless=HEADLESS,
args=['--disable-infobars',
f'--window-size={WINDOW_WIDTH},{WINDOW_HEIGHT}'])
tab = await browser.newPage()
await tab.setViewport({'width': WINDOW_WIDTH, 'height': WINDOW_HEIGHT})
在这里我们先声明了一个 browser 对象,代表 Pyppeteer 所用的浏览器对象,tab 代表新建的页面选项卡,这里把两项设置为全局变量,方便其他的方法调用。
另外定义了一个 init 方法,调用了 Pyppeteer 的 launch 方法,传入了 headless 为 HEADLESS,将其设置为非无头模式,另外还通过 args 指定了隐藏提示条并设定了窗口的宽高。
接下来我们像之前一样,定义一个通用的爬取方法,代码如下:
from pyppeteer.errors import TimeoutError
async def scrape_page(url, selector):
logging.info('scraping %s', url)
try:
await tab.goto(url)
await tab.waitForSelector(selector, options={
'timeout': TIMEOUT * 1000
})
except TimeoutError:
logging.error('error occurred while scraping %s', url, exc_info=True)
这里我们定义了一个 scrape_page 方法,它接收两个参数,一个是 url,代表要爬取的链接,使用 goto 方法调用即可;另外一个是 selector,即要等待渲染出的节点对应的 CSS 选择器,这里我们使用 waitForSelector 方法并传入了 selector,并通过 options 指定了最长等待时间。
这样的话在运行时页面会首先访问这个 URL,然后等待某个符合 selector 的节点加载出来,最长等待 10 秒,如果 10 秒内加载出来了,那就接着往下执行,否则抛出异常,捕获 TimeoutError 并输出错误日志。
接下来,我们就实现一下爬取列表页的方法,代码实现如下:
async def scrape_index(page):
url = INDEX_URL.format(page=page)
await scrape_page(url, '.item .name')
这里我们定义了 scrape_index 方法来爬取页面,其接受一个参数 page,代表要爬取的页码,这里我们首先通过 INDEX_URL 构造了列表页的 URL,然后调用 scrape_page 方法传入了 url 和要等待加载的选择器。
这里的选择器我们使用的是 .item .name,这就是列表页中每部电影的名称,如果这个加载出来了,那么就代表页面加载成功了,如图所示。
好,接下来我们可以再定义一个解析列表页的方法,提取出每部电影的详情页 URL,定义如下:
async def parse_index():
return await tab.querySelectorAllEval('.item .name', 'nodes => nodes.map(node => node.href)')
这里我们调用了 querySelectorAllEval 方法,它接收两个参数,第一个参数是 selector,代表要选择的节点对应的 CSS 选择器;第二个参数是 pageFunction,代表的是要执行的 JavaScript 方法,这里需要传入的是一段 JavaScript 字符串,整个方法的作用是选择 selector 对应的节点,然后对这些节点通过 pageFunction 定义的逻辑抽取出对应的结果并返回。
所以这里第一个参数 selector 就传入电影名称对应的节点,其实是超链接 a 节点。由于提取结果有多个,所以这里 JavaScript 对应的 pageFunction 输入参数就是 nodes,输出结果是调用了 map 方法得到每个 node,然后调用 node 的 href 属性即可。这样返回结果就是当前列表页的所有电影的详情页 URL 组成的列表了。
好,接下来我们来串联调用一下看看,代码实现如下:
import asyncio
async def main():
await init()
try:
for page in range(1, TOTAL_PAGE + 1):
await scrape_index(page)
detail_urls = await parse_index()
logging.info('detail_urls %s', detail_urls)
finally:
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
这里我们定义了一个 mian 方法,将前面定义的几个方法串联调用了一下。首先调用了 init 方法,然后循环遍历页码,调用了 scrape_index 方法爬取了每一页列表页,接着我们调用了 parse_index 方法,从列表页中提取出详情页的每个 URL,然后输出结果。
运行结果如下:
2020-04-08 13:54:28,879 - INFO: scraping https://dynamic2.scrape.center/page/1
2020-04-08 13:54:31,411 - INFO: detail_urls ['https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx', ...,
'https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI5', 'https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIxMA==']
2020-04-08 13:54:31,411 - INFO: scraping https://dynamic2.scrape.center/page/2
由于内容较多,这里省略了部分内容。
在这里可以看到,每一次的返回结果都会是当前列表页提取出来的所有详情页 URL 组成的列表,我们下一步就可以用这些 URL 来接着爬取了。
爬取详情页
拿到详情页的 URL 之后,下一步就是爬取每一个详情页然后提取信息了,首先我们定义一个爬取详情页的方法,代码如下:
async def scrape_detail(url):
await scrape_page(url, 'h2')
代码非常简单,就是直接调用了 scrape_page 方法,然后传入了要等待加载的节点的选择器,这里我们就直接用了 h2 了,对应的就是详情页的电影名称,如图所示。

如果顺利运行,那么当前 Pyppeteer 就已经成功加载出详情页了,下一步就是提取里面的信息了。
接下来我们再定义一个提取详情信息的方法,代码如下:
async def parse_detail():
url = tab.url
name = await tab.querySelectorEval('h2', 'node => node.innerText')
categories = await tab.querySelectorAllEval('.categories button span', 'nodes => nodes.map(node => node.innerText)')
cover = await tab.querySelectorEval('.cover', 'node => node.src')
score = await tab.querySelectorEval('.score', 'node => node.innerText')
drama = await tab.querySelectorEval('.drama p', 'node => node.innerText')
return {
'url': url,
'name': name,
'categories': categories,
'cover': cover,
'score': score,
'drama': drama
}
这里我们定义了一个 parse_detail 方法,提取了 URL、名称、类别、封面、分数、简介等内容,提取方式如下:
-
URL:直接调用 tab 对象的 url 属性即可获取当前页面的 URL。
-
名称:由于名称只有一个节点,所以这里我们调用了 querySelectorEval 方法来提取,而不是querySelectorAllEval,第一个参数传入 h2,提取到了名称对应的节点,然后第二个参数传入提取的 pageFunction,调用了 node 的 innerText 属性提取了文本值,即电影名称。
-
类别:类别有多个,所以我们这里调用了 querySelectorAllEval 方法来提取,其对应的 CSS 选择器为 .categories button span,可以选中多个类别节点。接下来还是像之前提取详情页 URL 一样,pageFunction 使用 nodes 参数,然后调用 map 方法提取 node 的 innerText 就得到所有类别结果了。
-
封面:同样地,可以使用 CSS 选择器 .cover 直接获取封面对应的节点,但是由于其封面的 URL 对应的是 src 这个属性,所以这里提取的是 src 属性。
-
分数:分数对应的 CSS 选择器为 .score ,类似的原理,提取 node 的 innerText 即可。
-
简介:同样可以使用 CSS 选择器 .drama p 直接获取简介对应的节点,然后调用 innerText 属性提取文本即可。
最后我们将提取结果汇总成一个字典然后返回即可。
接下来 main 方法里面,我们增加 scrape_detail 和 parse_detail 方法的调用,main 方法改写如下:
async def main():
await init()
try:
for page in range(1, TOTAL_PAGE + 1):
await scrape_index(page)
detail_urls = await parse_index()
for detail_url in detail_urls:
await scrape_detail(detail_url)
detail_data = await parse_detail()
logging.info('data %s', detail_data)
finally:
await browser.close()
重新看下运行结果,运行结果如下:
2020-04-08 14:12:39,564 - INFO: scraping https://dynamic2.scrape.center/page/1
2020-04-08 14:12:42,935 - INFO: scraping https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
2020-04-08 14:12:45,781 - INFO: data {'url': 'https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx', 'name': '霸王别姬 - Farewell My Concubine', 'categories': ['剧情', '爱情'], 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'score': '9.5', 'drama': '影片借一出《霸王别姬》的京戏,牵扯出三个人之间一段随时代风云变幻的爱恨情仇。段小楼(张丰毅 饰)与程蝶衣(张国荣 饰)是一对打小一起长大的师兄弟,两人一个演生,一个饰旦,一向配合天衣无缝,尤其一出《霸王别姬》,更是誉满京城,为此,两人约定合演一辈子《霸王别姬》。但两人对戏剧与人生关系的理解有本质不同,段小楼深知戏非人生,程蝶衣则是人戏不分。段小楼在认为该成家立业之时迎娶了名妓菊仙(巩俐 饰),致使程蝶衣认定菊仙是可耻的第三者,使段小楼做了叛徒,自此,三人围绕一出《霸王别姬》生出的爱恨情仇战开始随着时代风云的变迁不断升级,终酿成悲剧。'}
2020-04-08 14:12:45,782 - INFO: scraping https://dynamic2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIy
这里可以看到,首先先爬取了列表页,然后提取出了详情页之后接着开始爬详情页,然后提取出我们想要的电影信息之后,再接着去爬下一个详情页。
这样,所有的详情页都会被我们爬取下来啦。
数据存储
最后,我们再像之前一样添加一个数据存储的方法,为了方便,这里还是保存为 JSON 文本文件,实现如下:
import json
from os import makedirs
from os.path import exists
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
async def save_data(data):
name = data.get('name')
data_path = f'{RESULTS_DIR}/{name}.json'
json.dump(data, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
这里原理和之前是完全相同的,但是由于这里我们使用的是 Pyppeteer,是异步调用,所以 save_data 方法前面需要加 async。
最后添加上 save_data 的调用,完整看下运行效果。
问题排查
在运行过程中,由于 Pyppeteer 本身实现的原因,可能连续运行 20 秒之后控制台就会出现如下错误:
pyppeteer.errors.NetworkError: Protocol Error (Runtime.evaluate): Session closed. Most likely the page has been closed.
其原因是 Pyppeteer 内部使用了 Websocket,在 Websocket 客户端发送 ping 信号 20 秒之后仍未收到 pong 应答,就会中断连接。
问题的解决方法和详情描述见 https://github.com/miyakogi/pyppeteer/issues/178,此时我们可以通过修改 Pyppeteer 源代码来解决这个问题,对应的代码修改见:https://github.com/miyakogi/pyppeteer/pull/160/files,即把 connect 方法添加 ping_interval=None, ping_timeout=None 两个参数即可。
另外也可以复写一下 Connection 的实现,其解决方案同样可以在 https://github.com/miyakogi/pyppeteer/pull/160 找到,如 patch_pyppeteer 的定义。
无头模式
最后如果代码能稳定运行了,我们可以将其改为无头模式,将 HEADLESS 修改为 True 即可,这样在运行的时候就不会弹出浏览器窗口了。
总结
本课时我们通过实例来讲解了 Pyppeteer 爬取一个完整网站的过程,从而对 Pyppeteer 的使用有进一步的掌握。
